4.6 billion is literally an astronomical figure. The richest star map of our galaxy, brought by Gaia space observatory, includes just under 2 billion stars. What does a view of 4.6 billion GitHub events really look like? What secrets and values can be discovered in such an enormous amount of data?
Here you go: OSSInsight.io can help you find the answer. It’s a useful insight tool that can give you the most updated open source intelligence, and help you deeply understand any single GitHub project or quickly compare any two projects by digging deep into 4.6 billion GitHub events in real time. Here are some ways you can play with it.
Compare any two GitHub projects
Do you wonder how different projects have performed and developed over time? Which project is worthy of more attention? OSSInsight.io can answer your questions via the Compare Projects page.
Let’s take the Kubernetes repository (K8s) and Docker’s Moby repository as examples and compare them in terms of popularity and coding vitality.
Popularity
To compare the popularity of two repositories, we use multiple metrics including the number of stars, the growth trend of stars over time, and stargazers’ geographic and employment distribution.
Number of stars
The line chart below shows the accumulated number of stars of K8s and Moby each year. According to the chart, Moby was ahead of K8s until late 2019. The star growth of Moby slowed after 2017 while K8s has kept a steady growth pace.

The star history of K8s and MobyGeographical distribution of stargazers
The map below shows the stargazers’ geographical distribution of Moby and K8s. As you can see, their stargazers are scattered around the world with the majority coming from the US, Europe, and China.
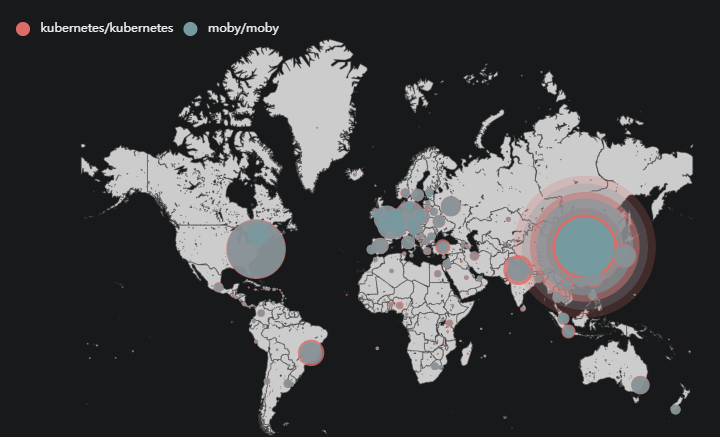
The geographical distribution of K8s and Moby stargazersEmployment distribution of stargazers
The chart below shows the stargazers’ employment of K8s (red) and Moby (dark blue). Both of their stargazers work in a wide range of industries, and most come from leading dotcom companies such as Google, Tencent, and Microsoft. The difference is that the top two companies of K8s’ stargazers are Google and Microsoft from the US, while Moby’s top two followers are Tencent and Alibaba from China.
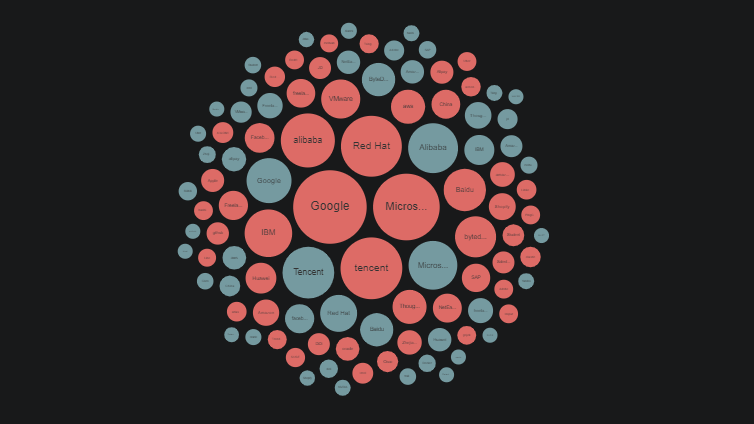
The employment distribution of K8s and Moby stargazers


