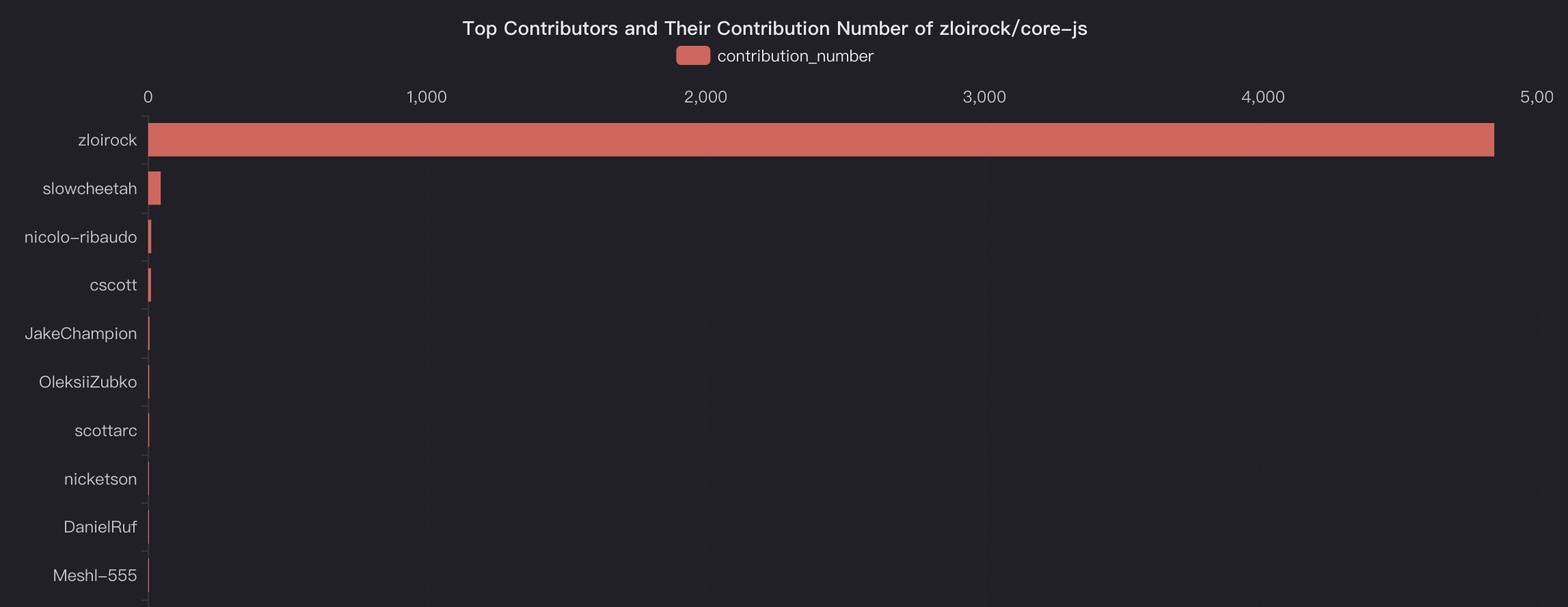
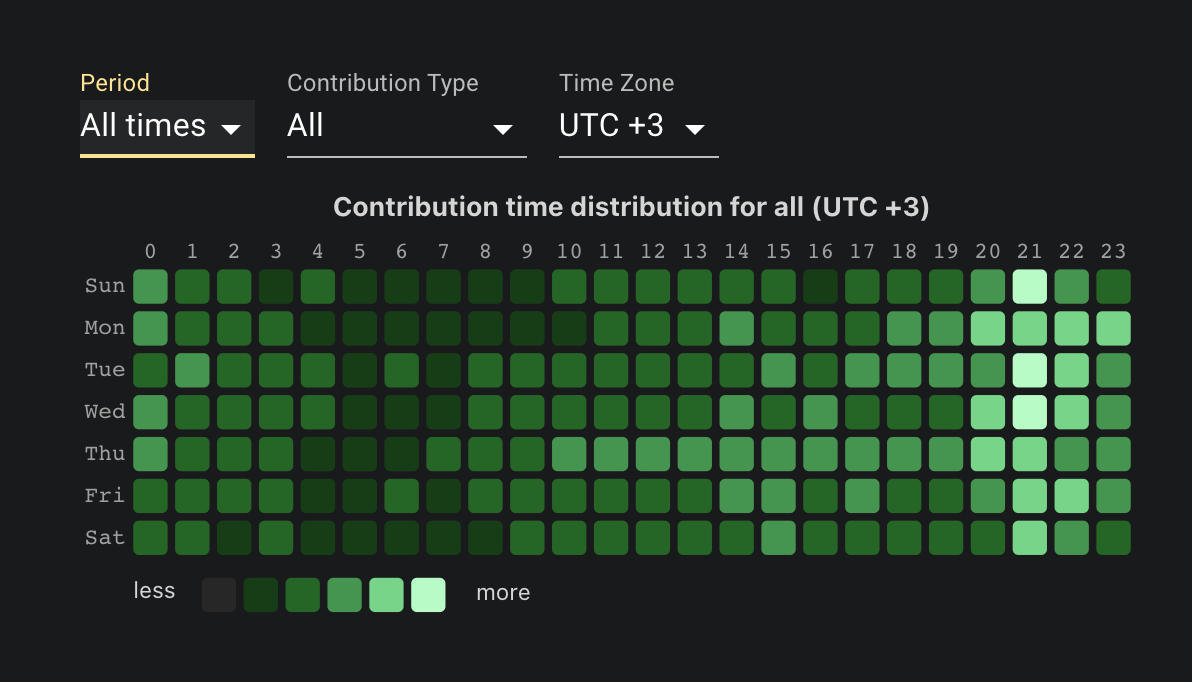
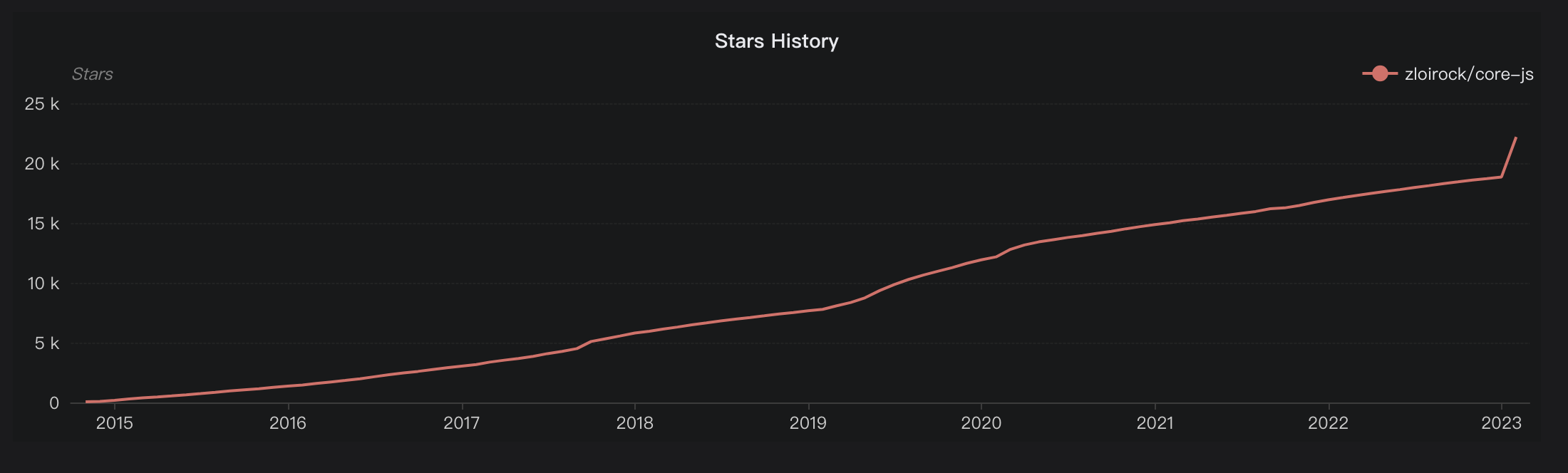
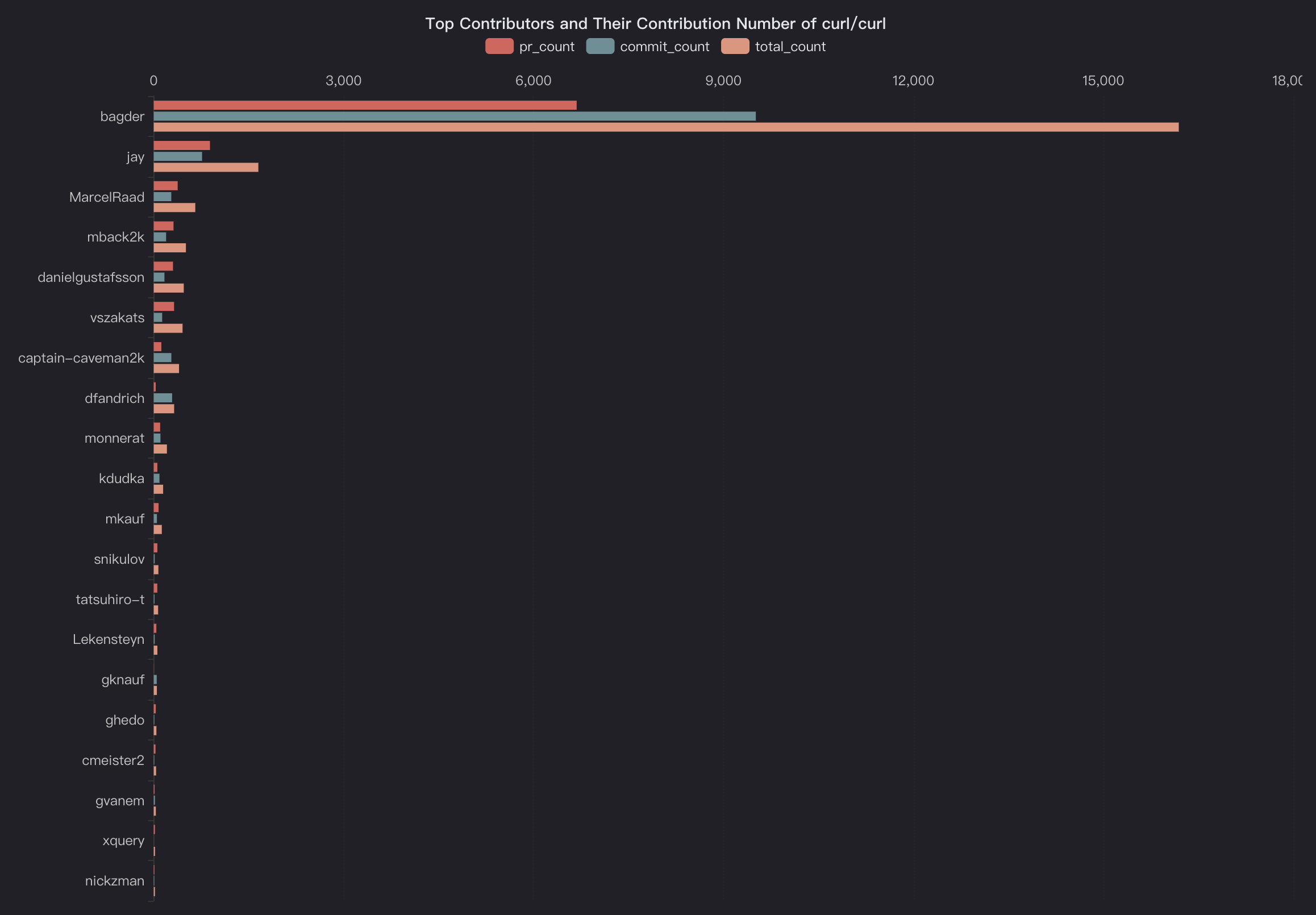
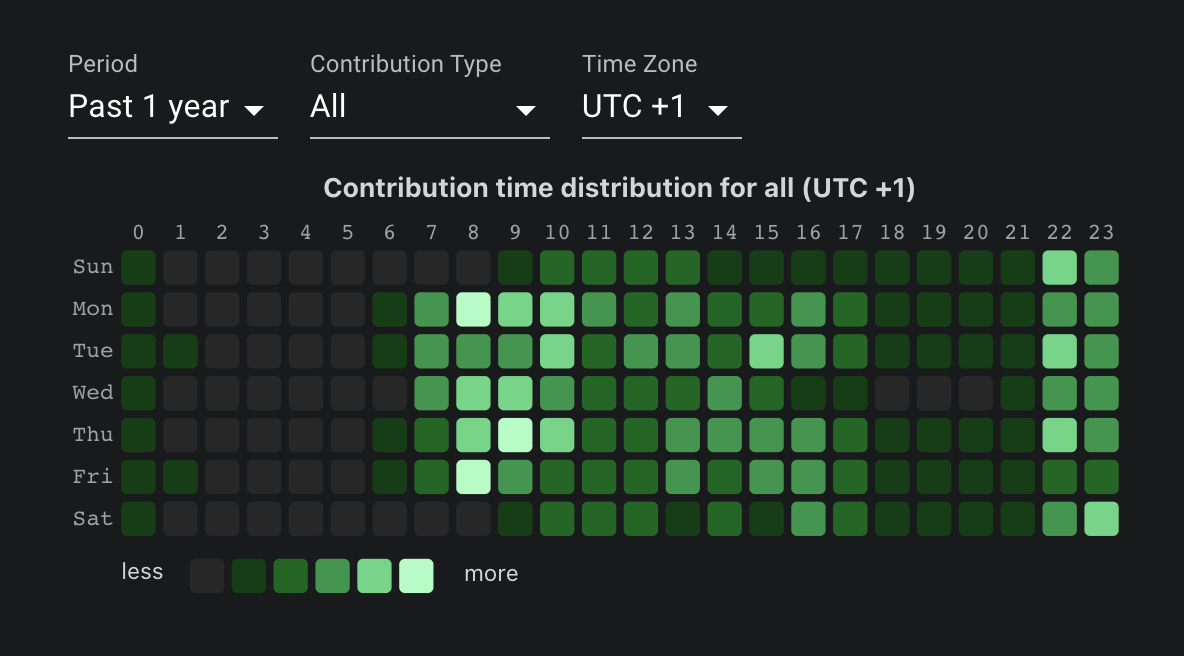
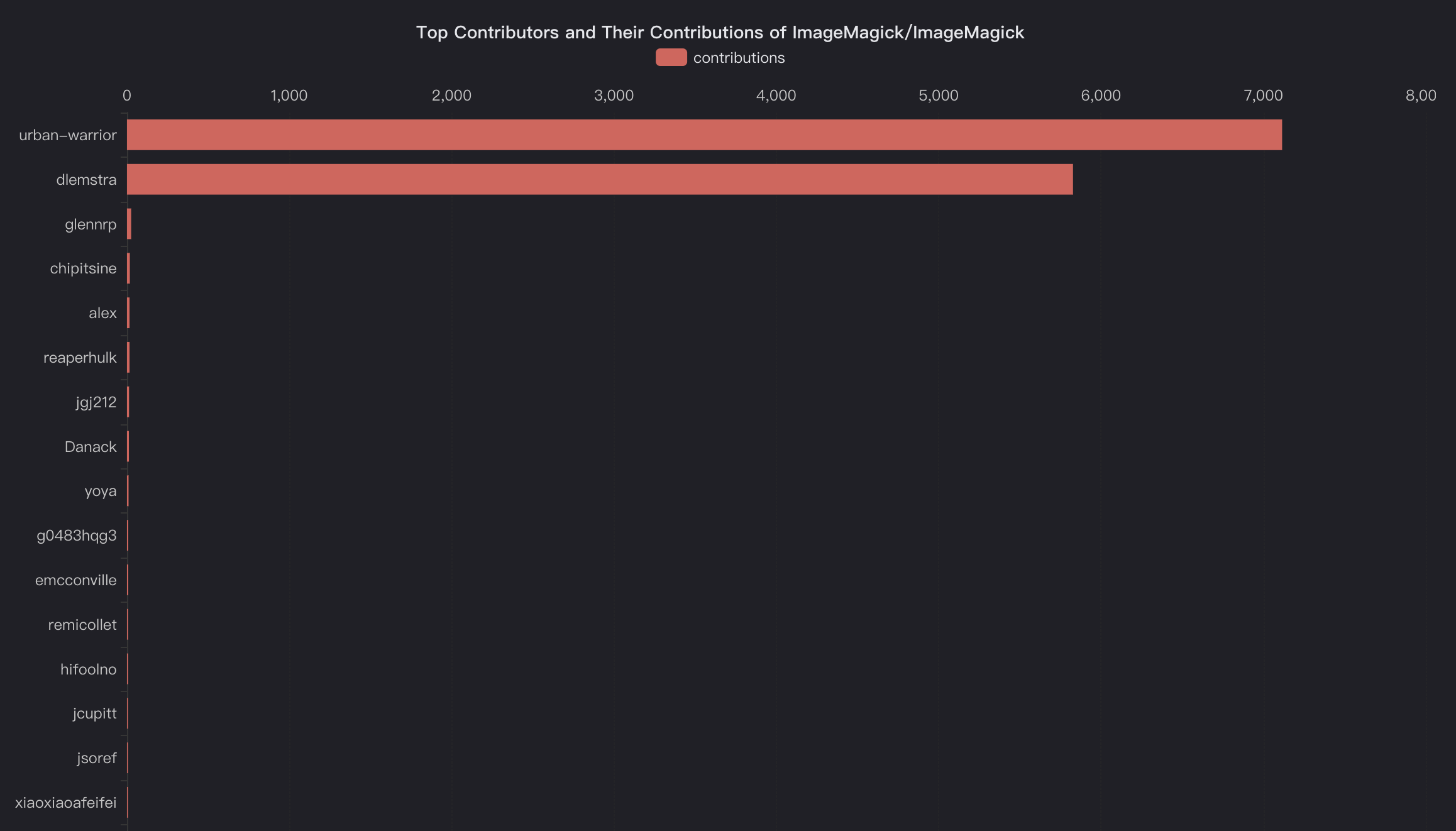
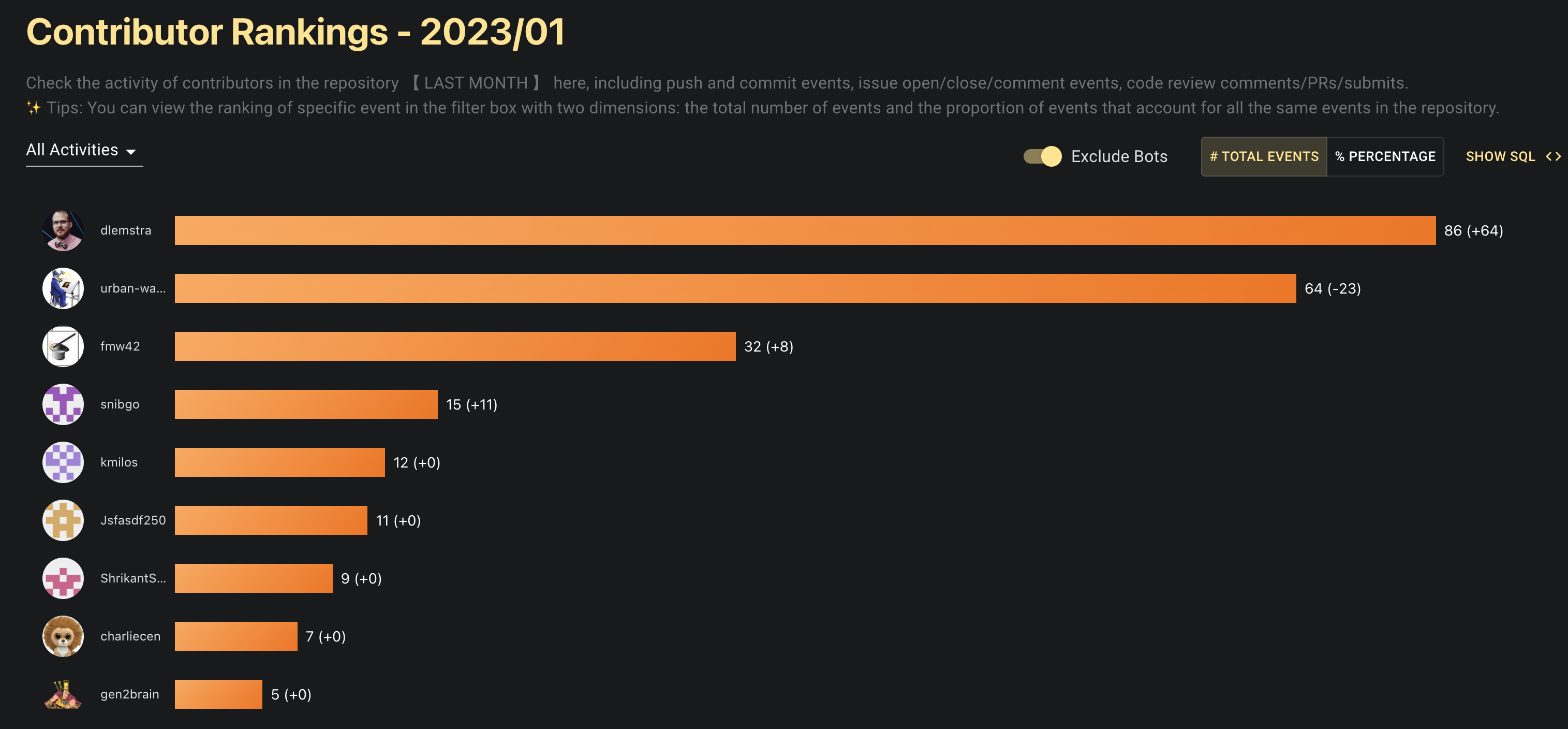
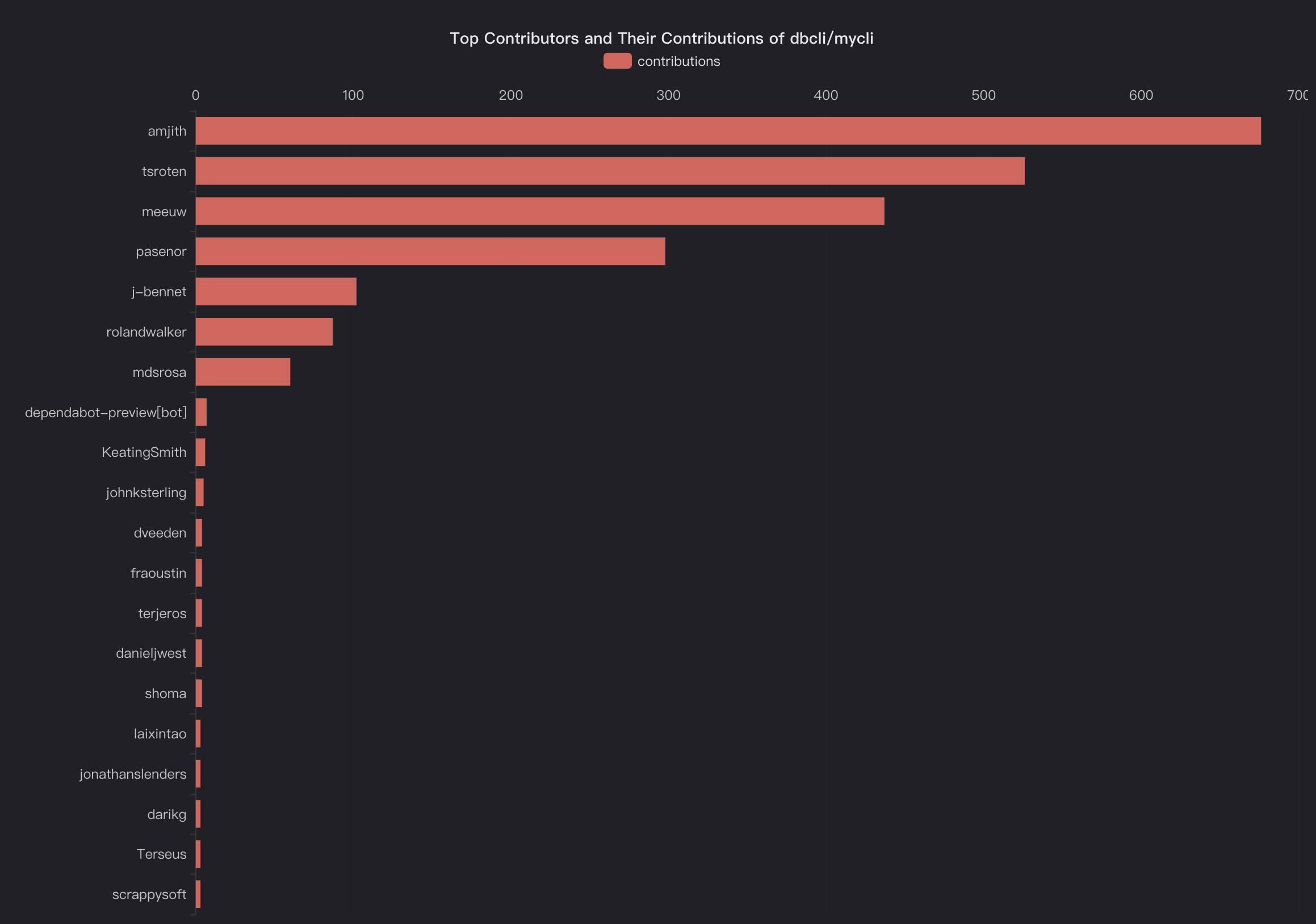
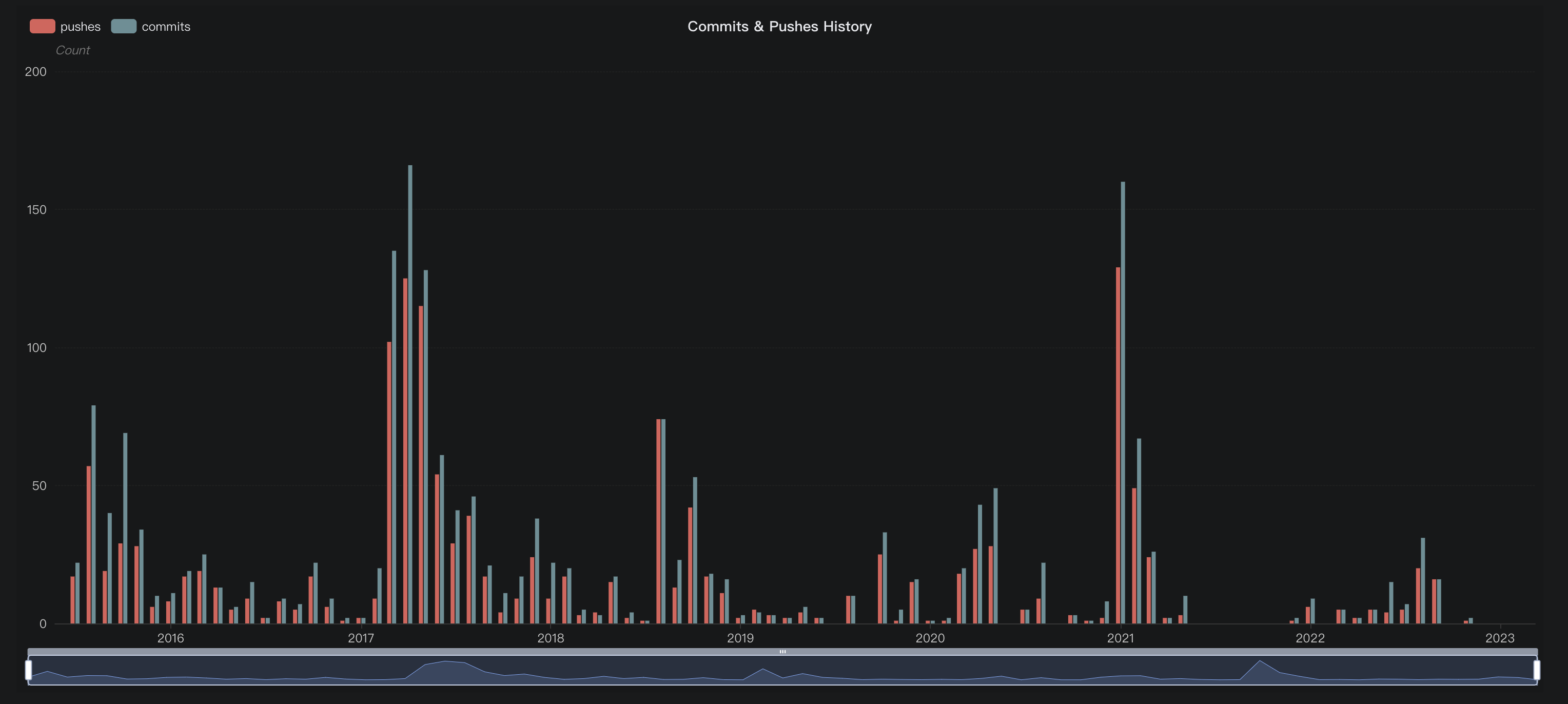
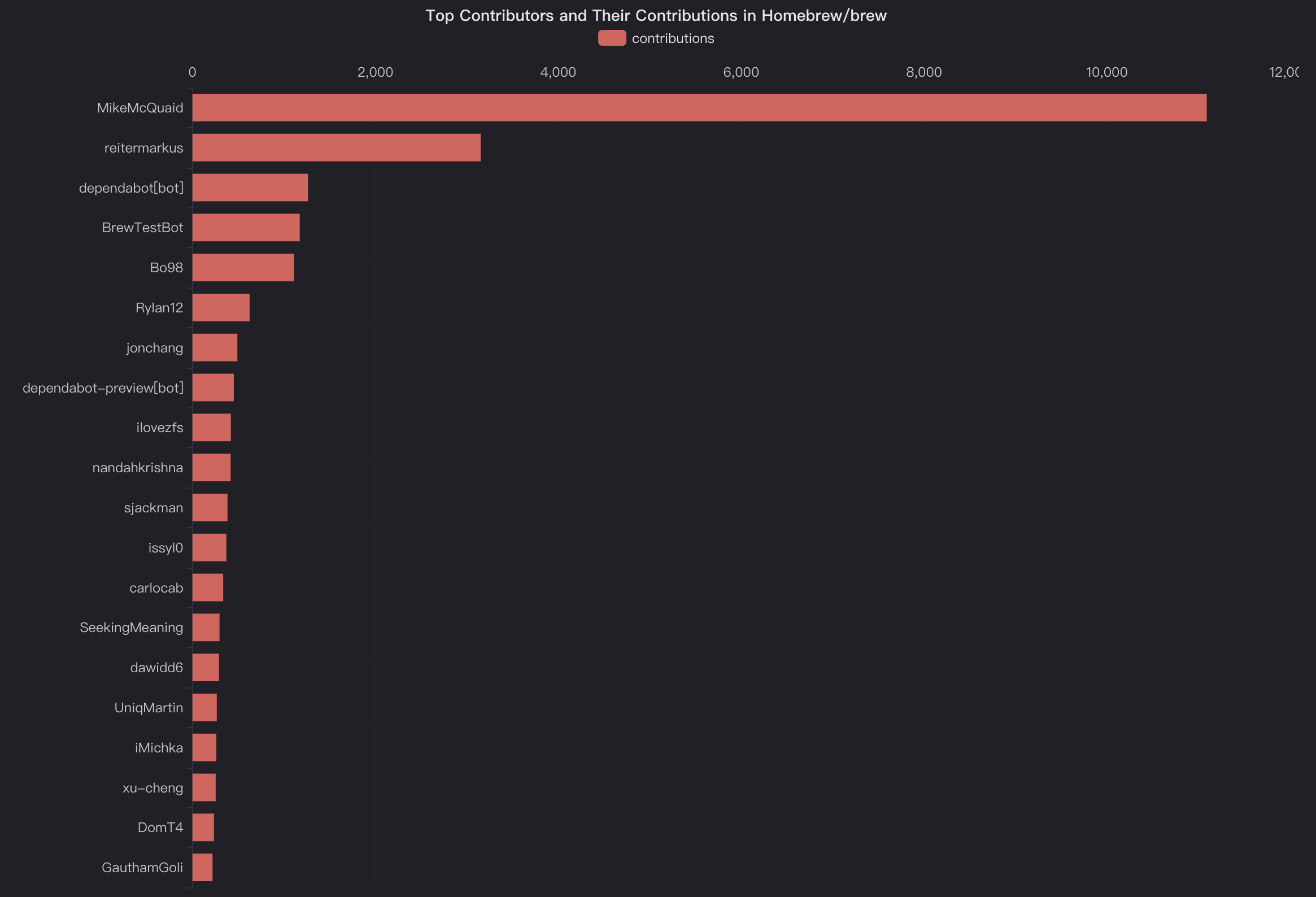
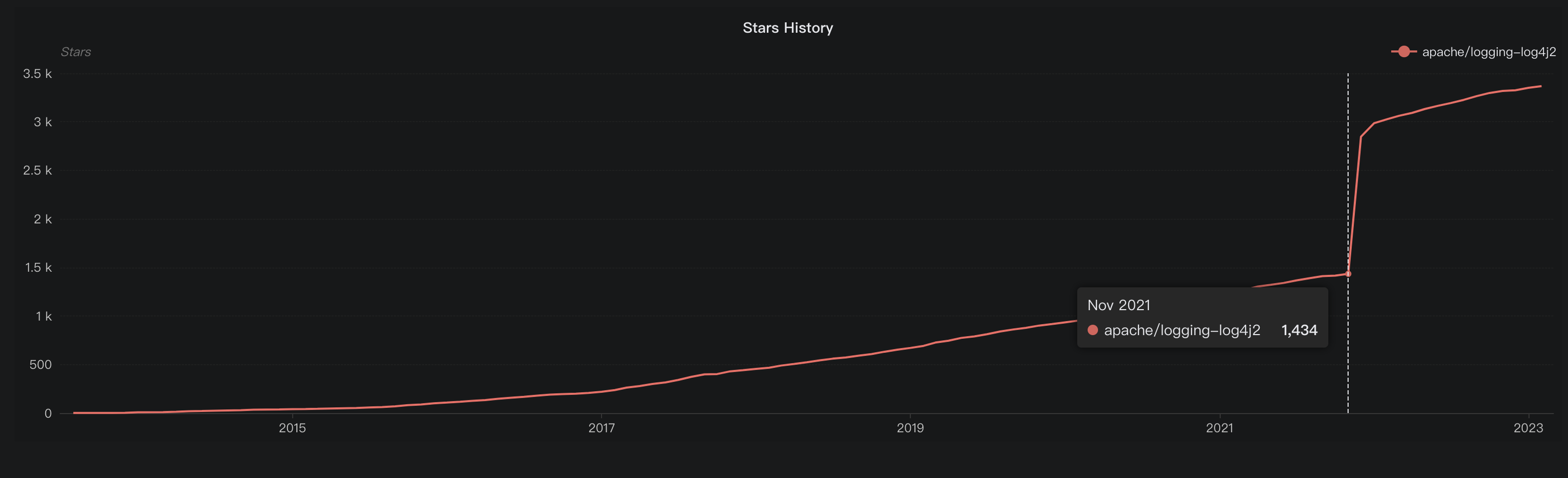
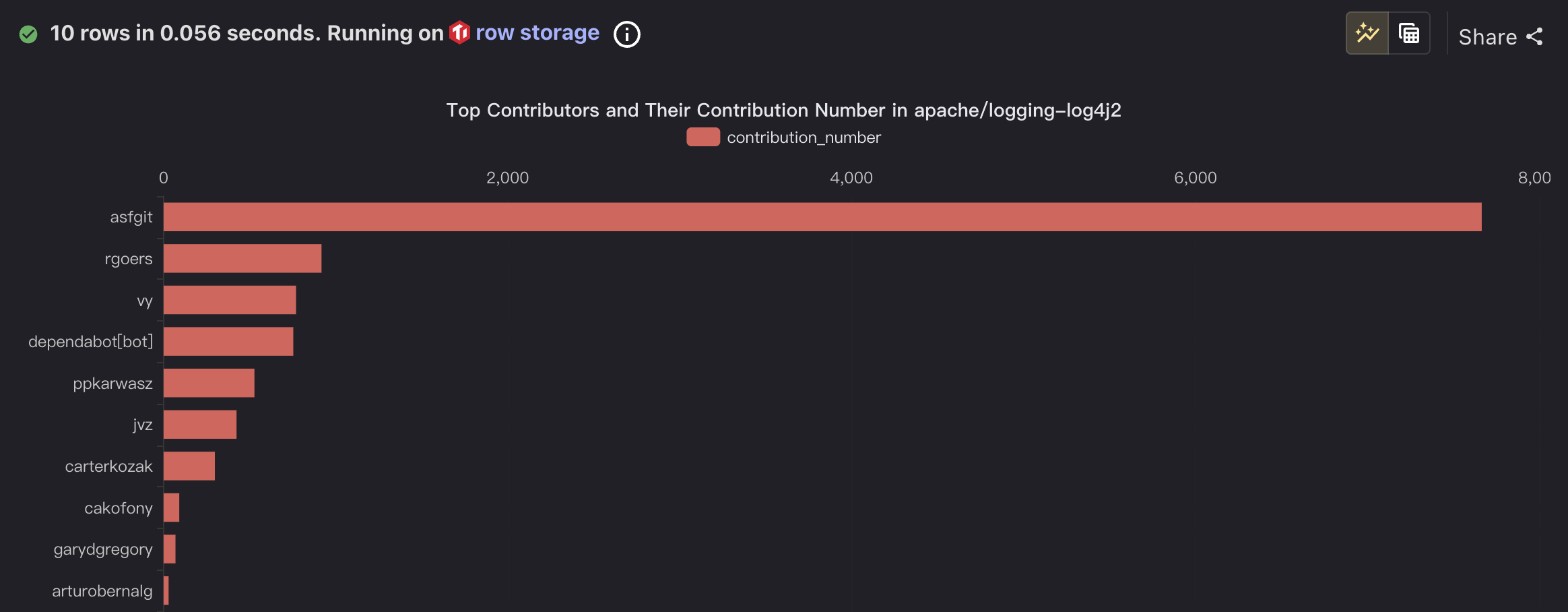
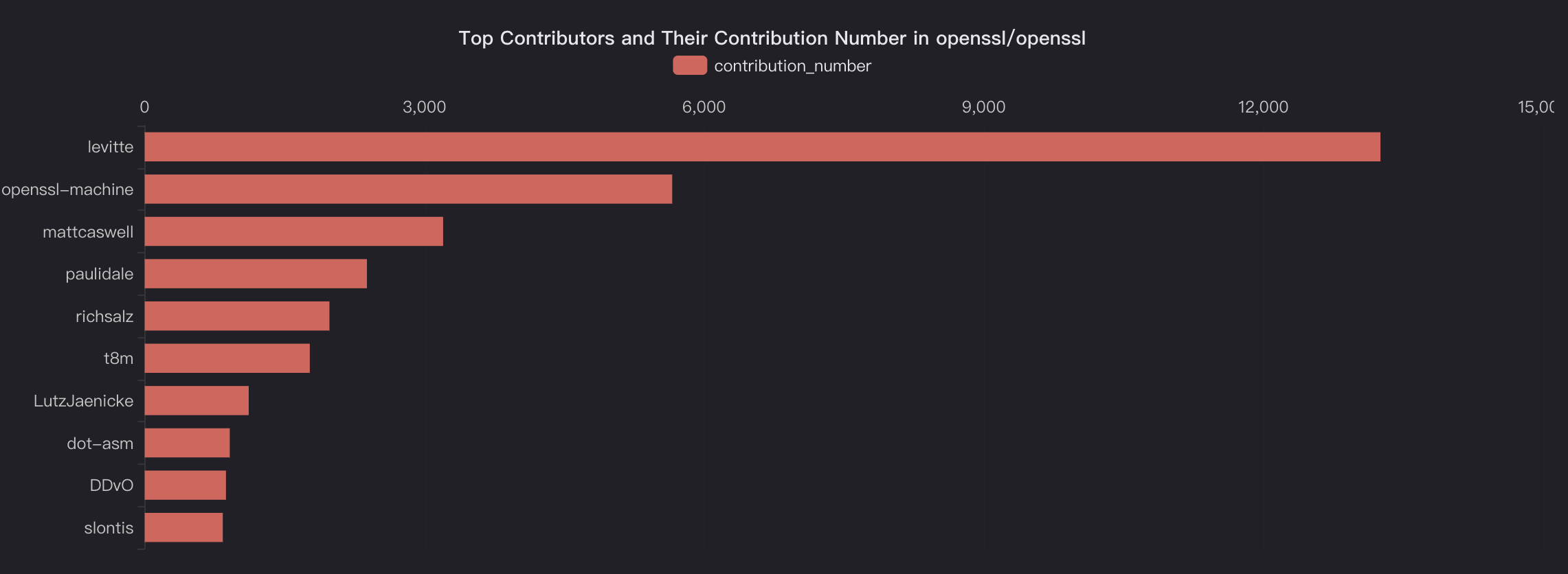
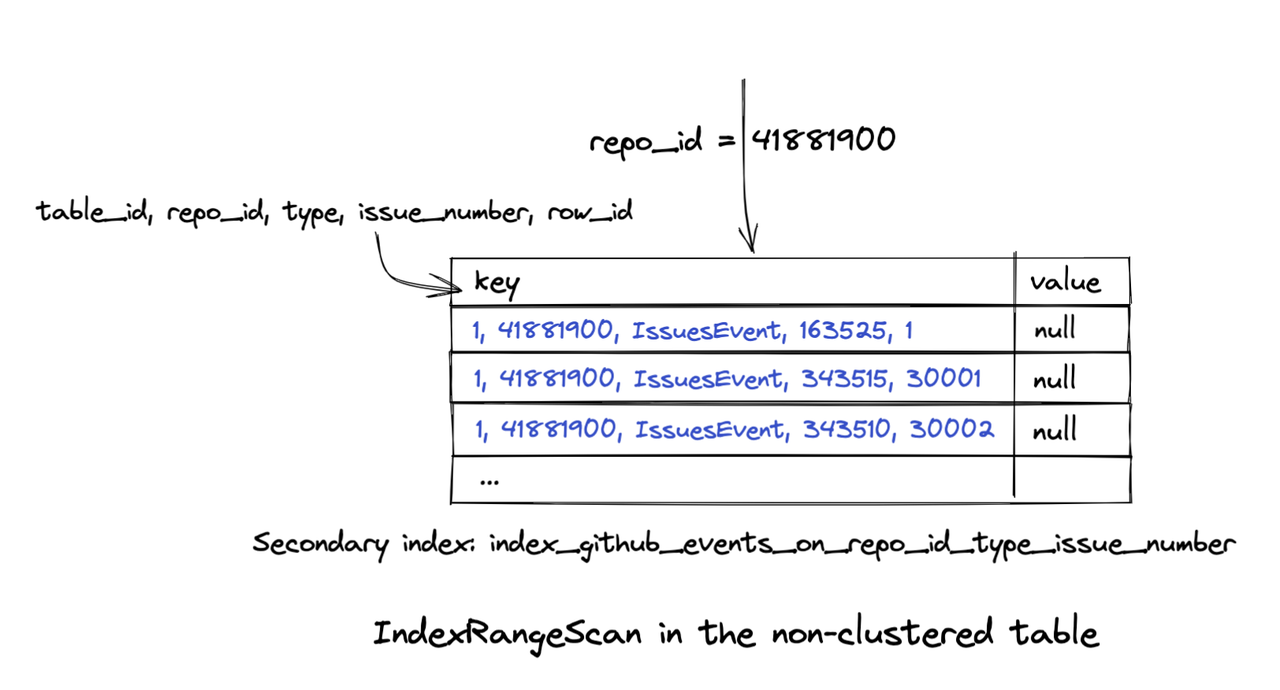
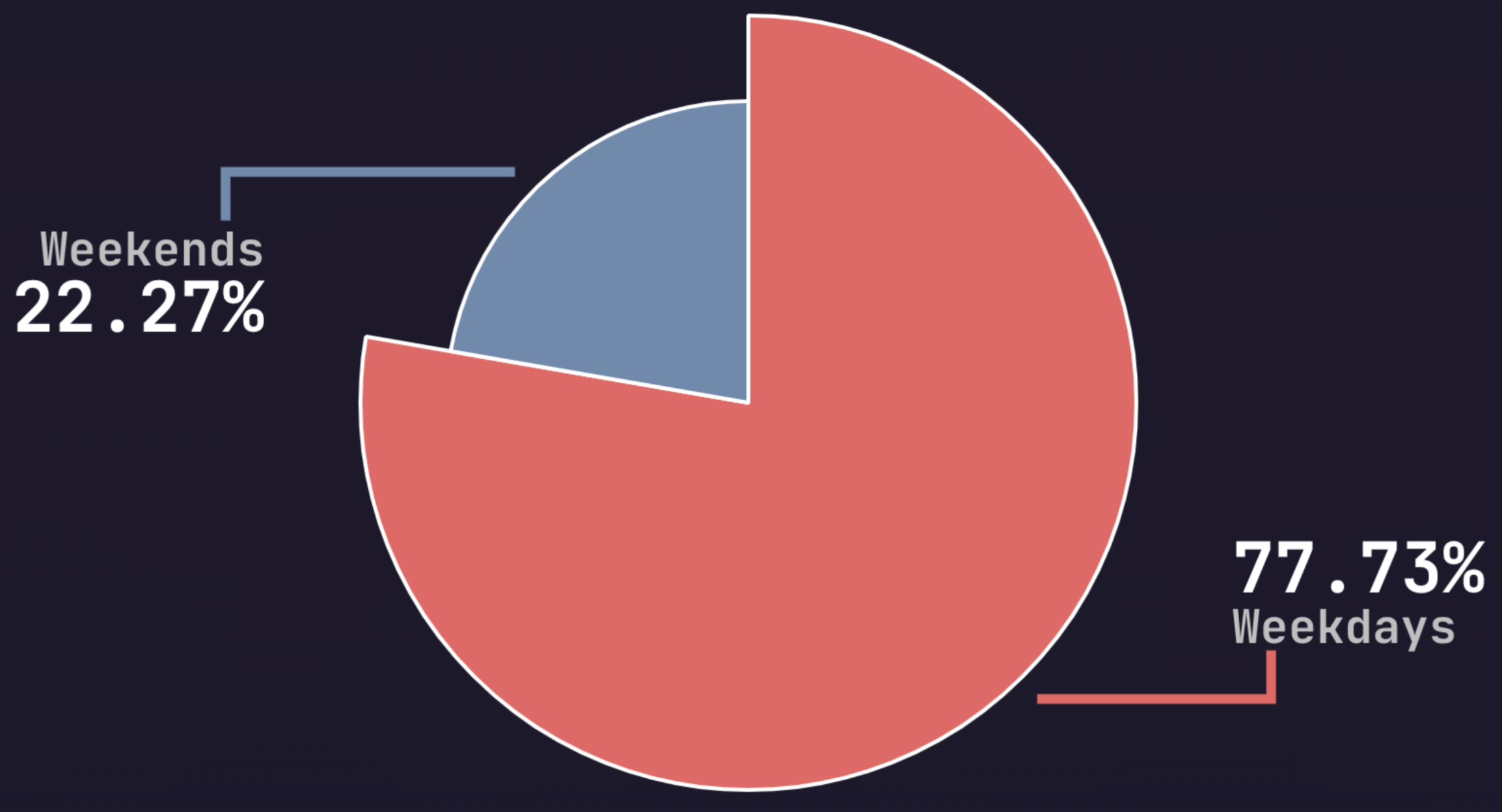
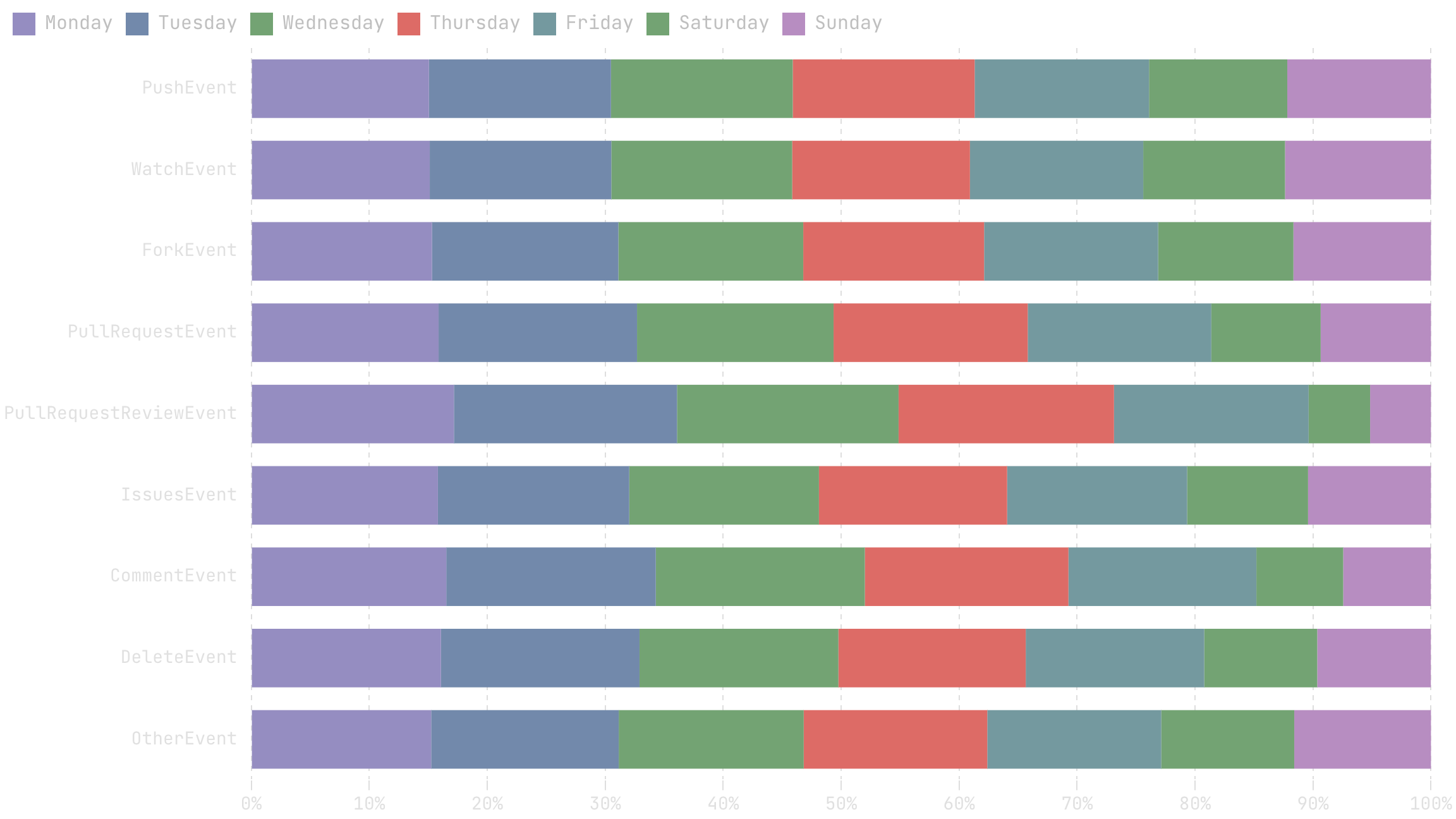
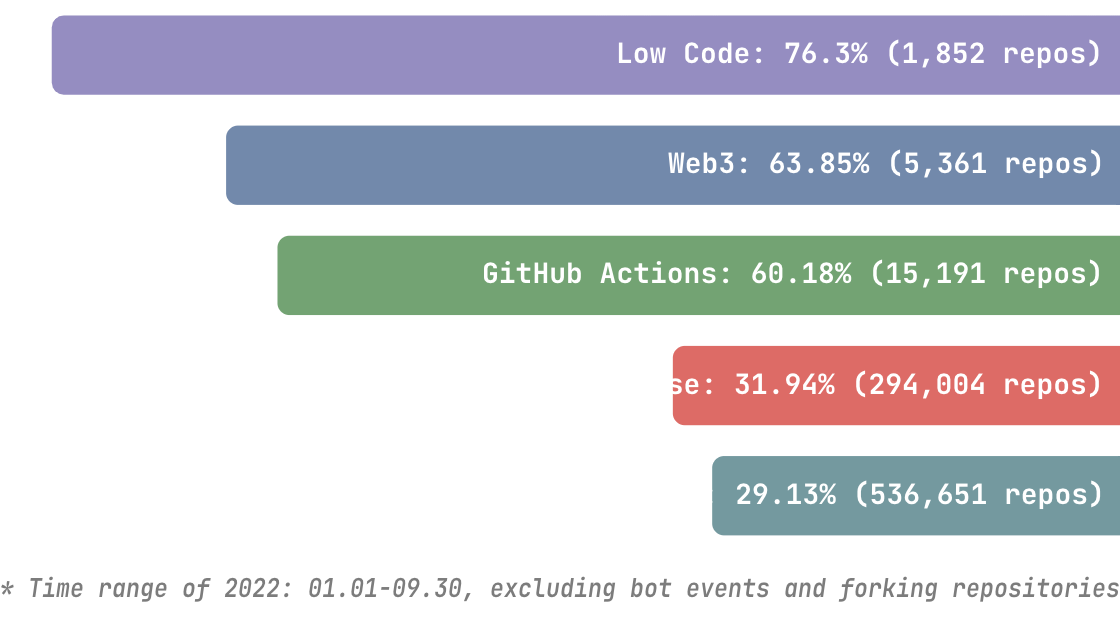
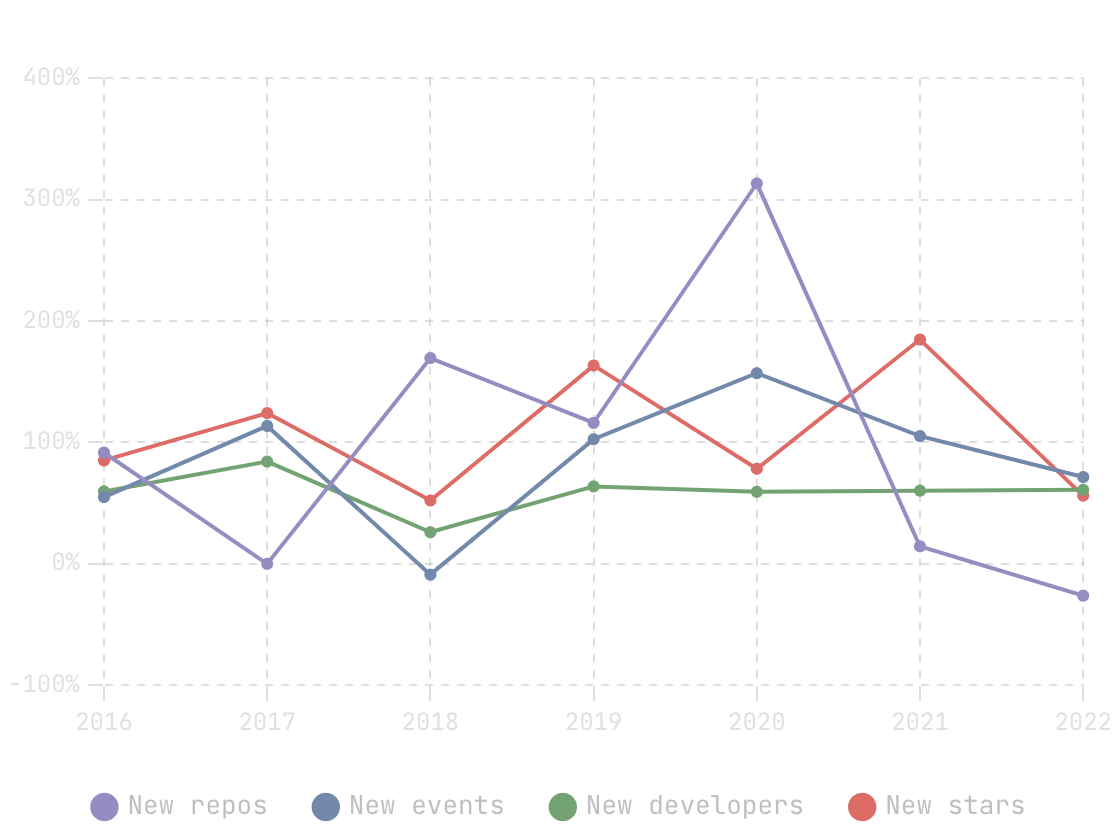
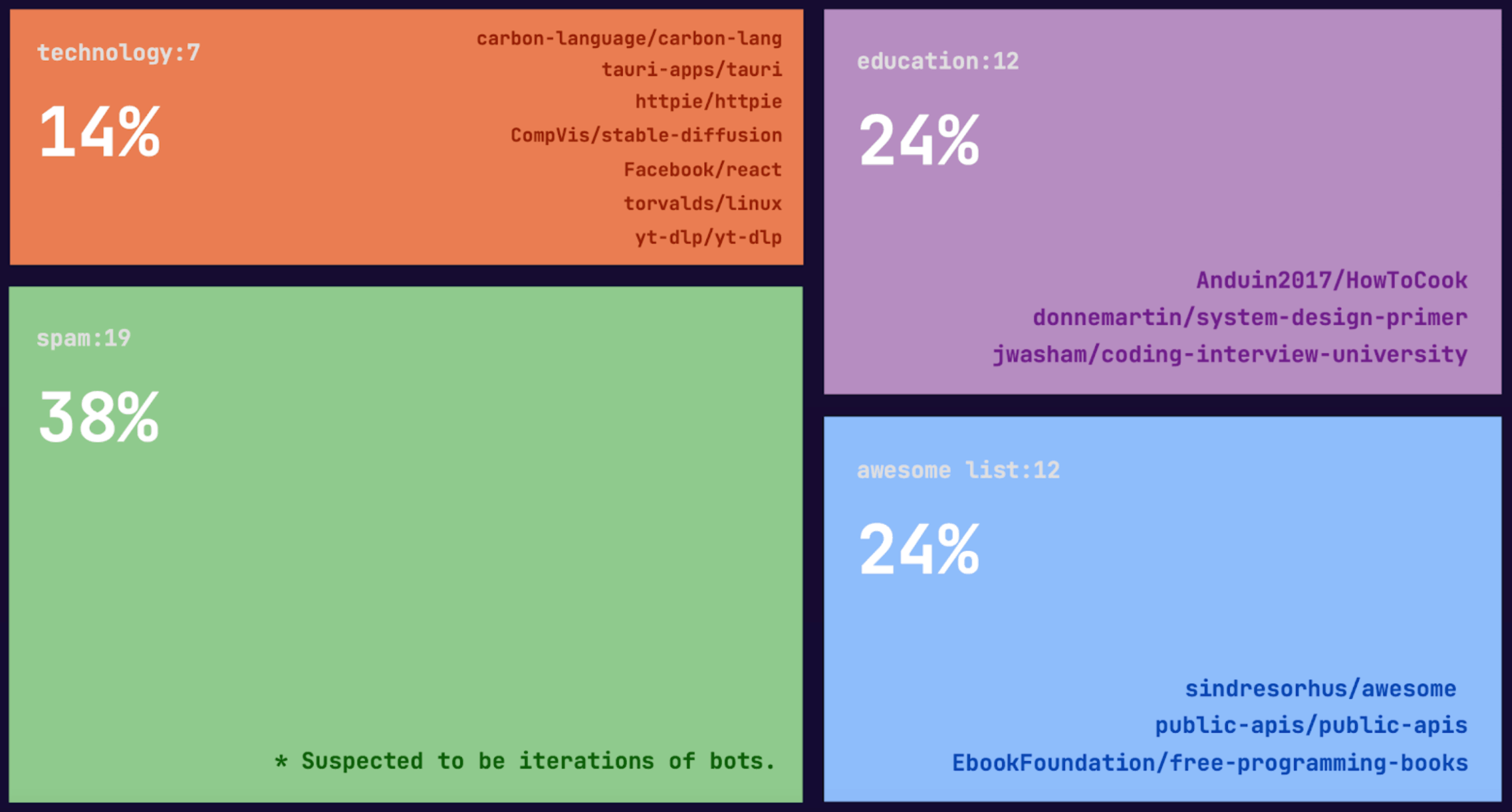
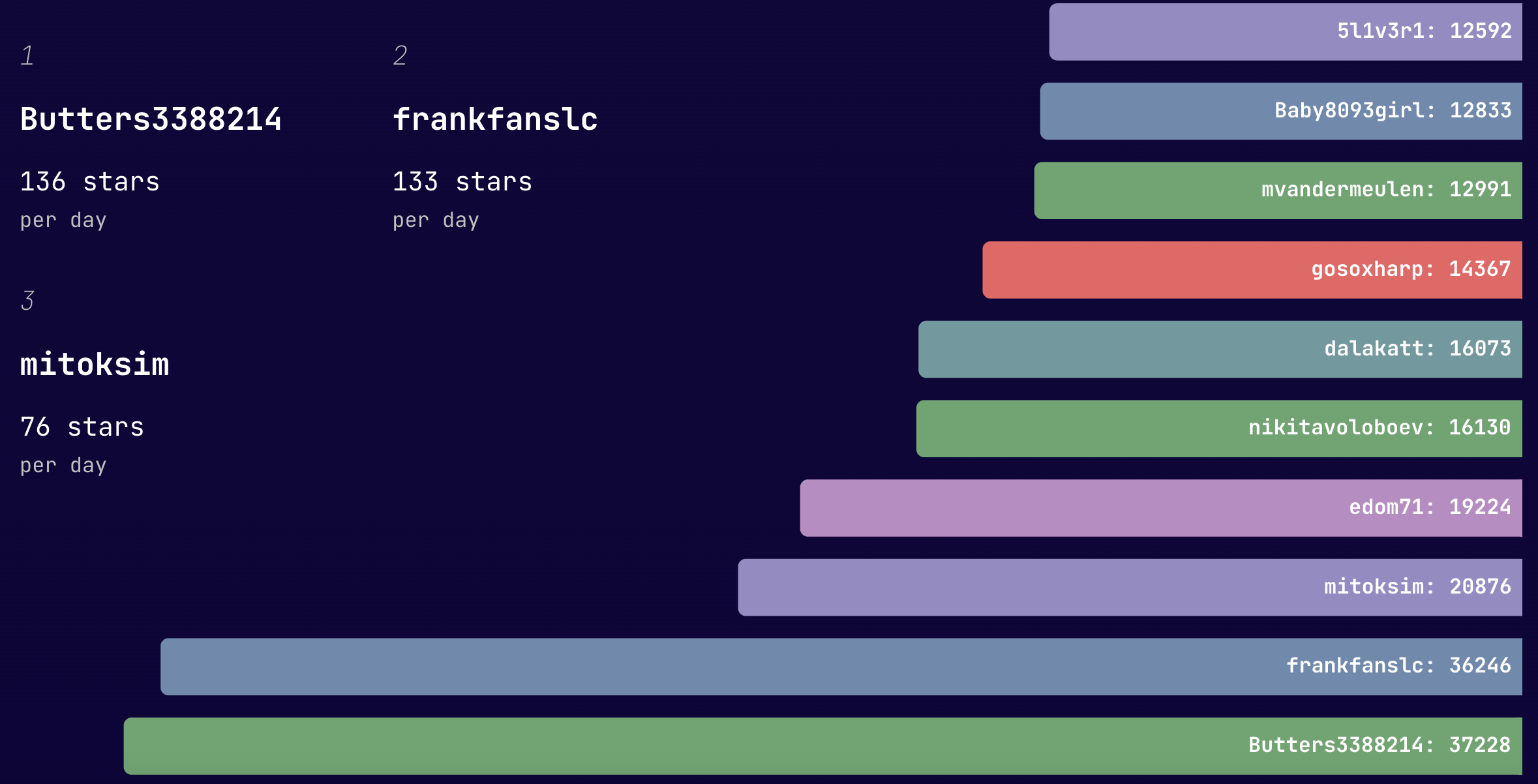
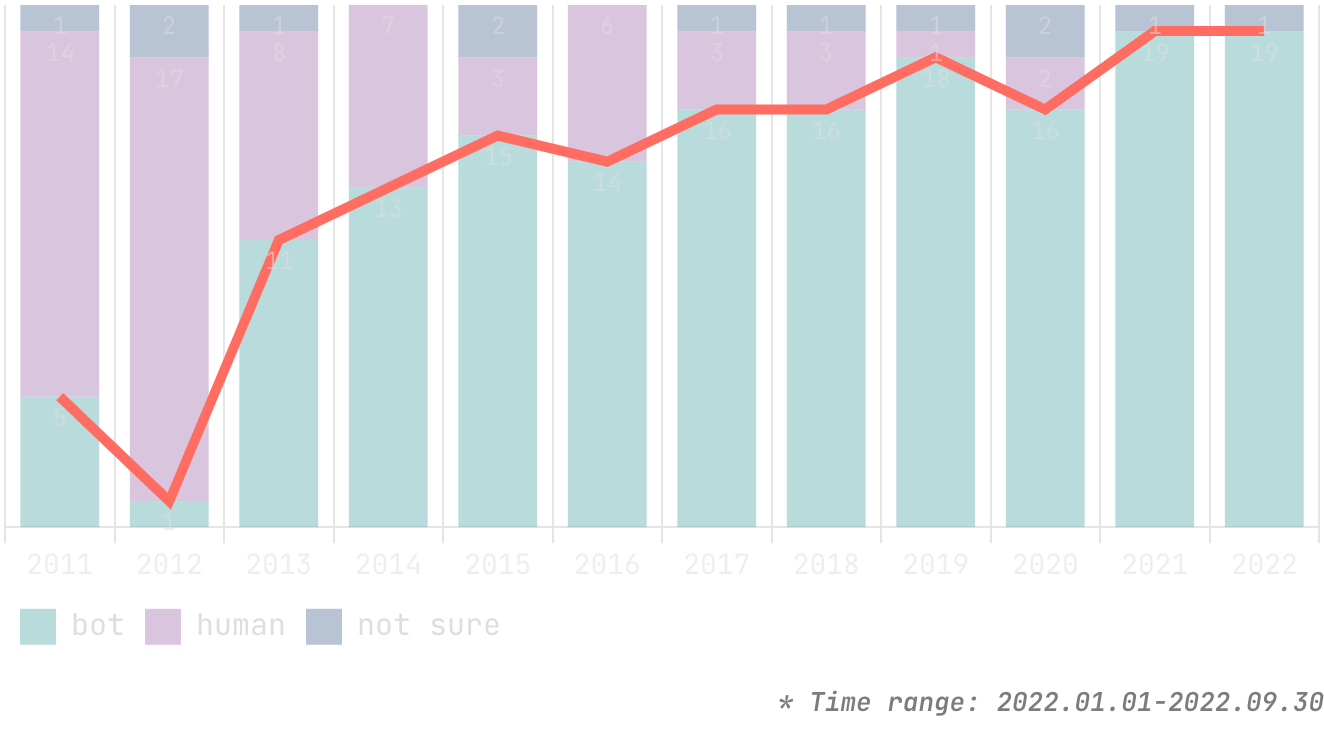
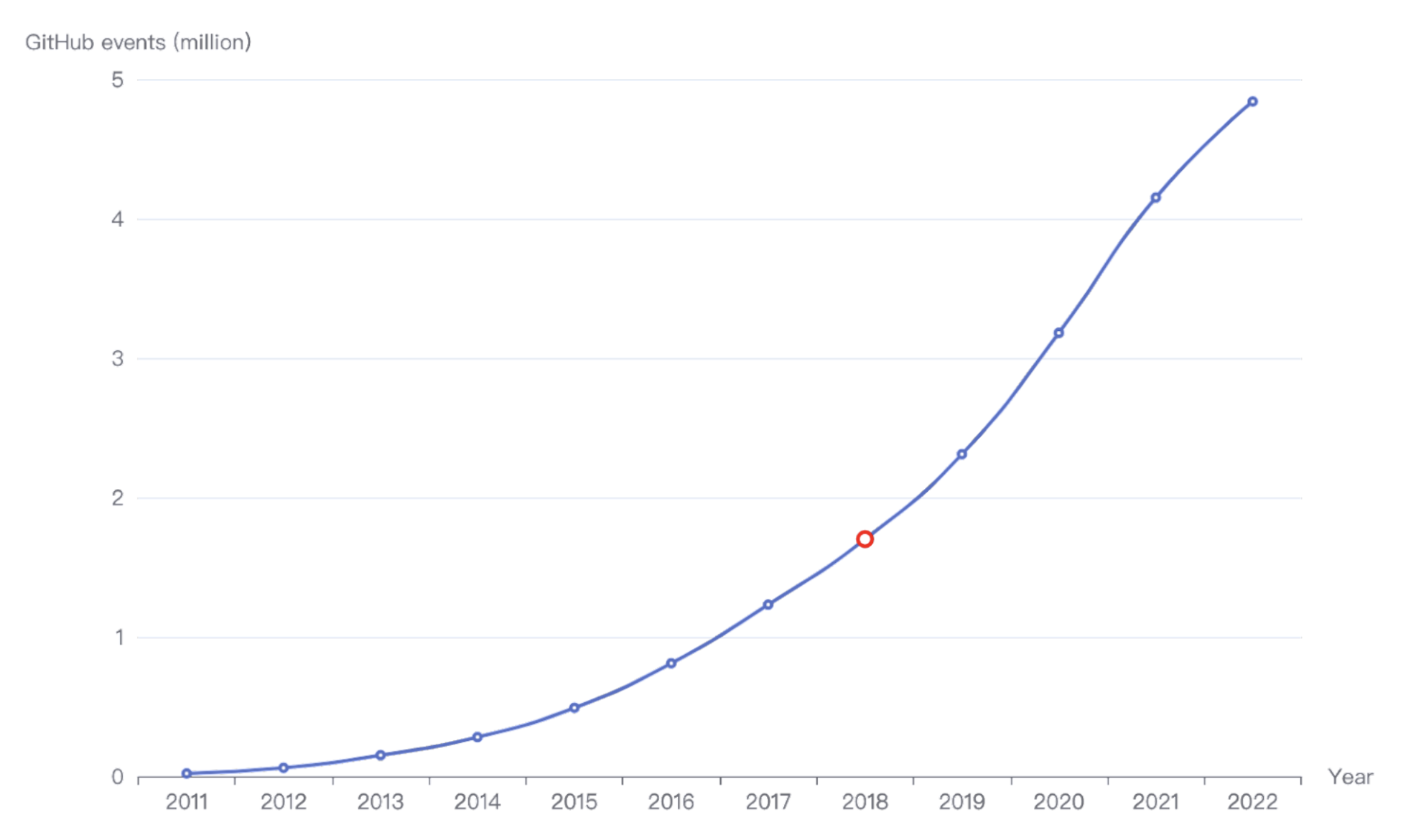
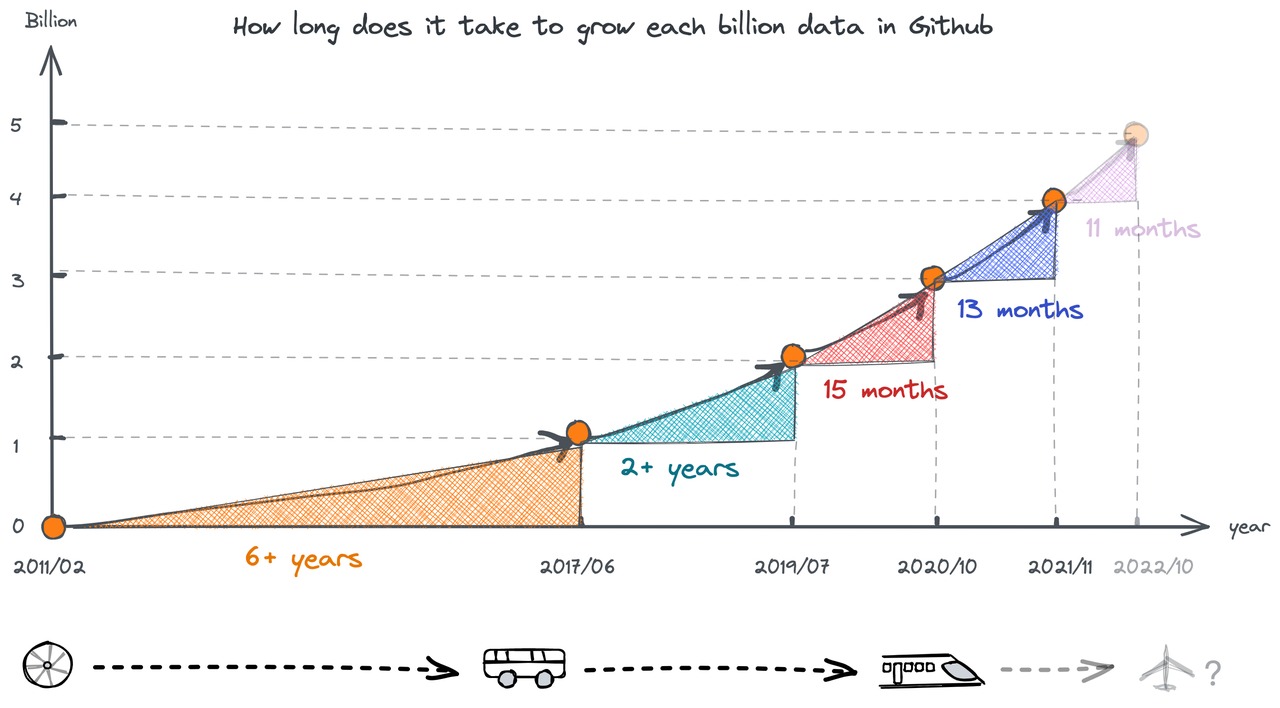
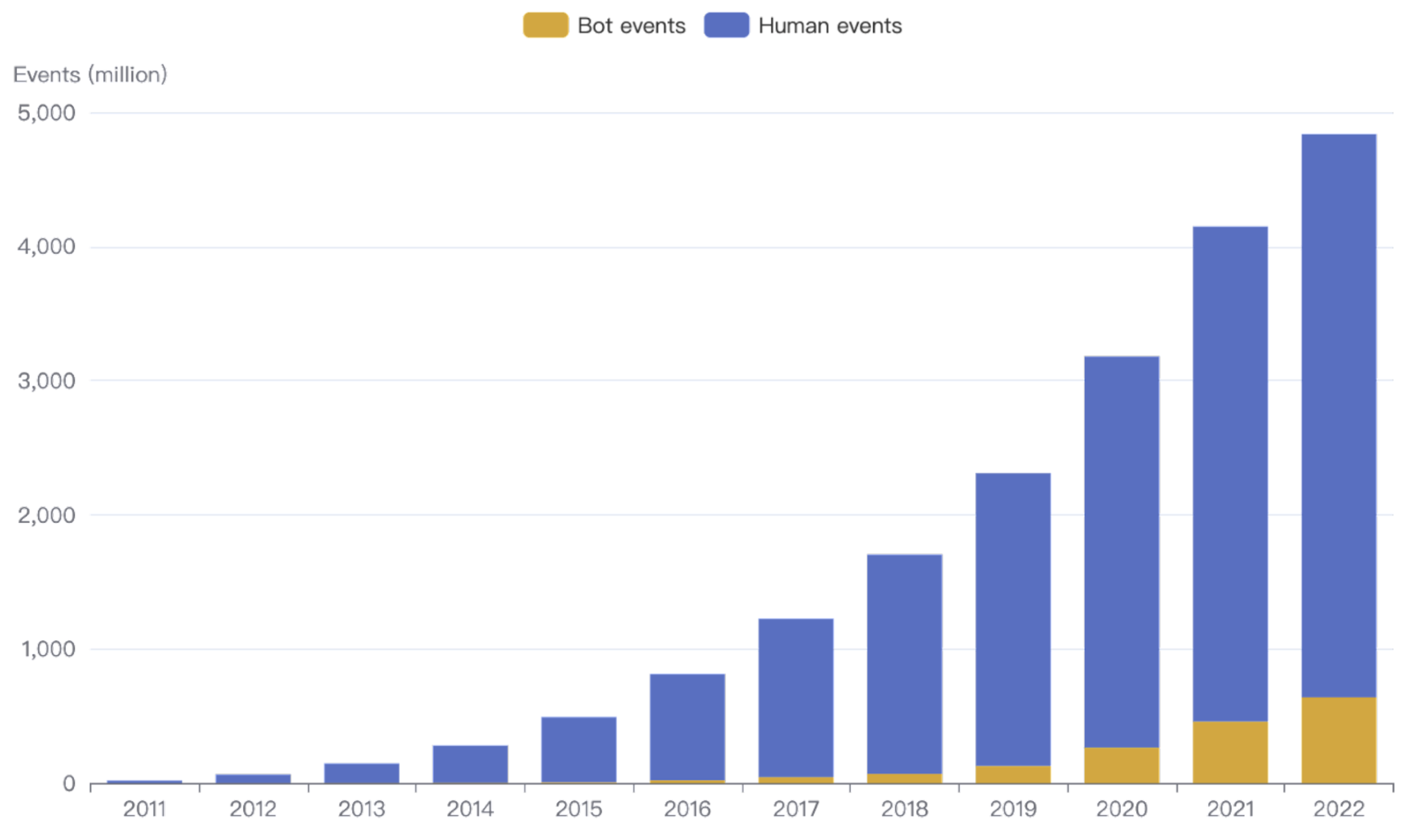
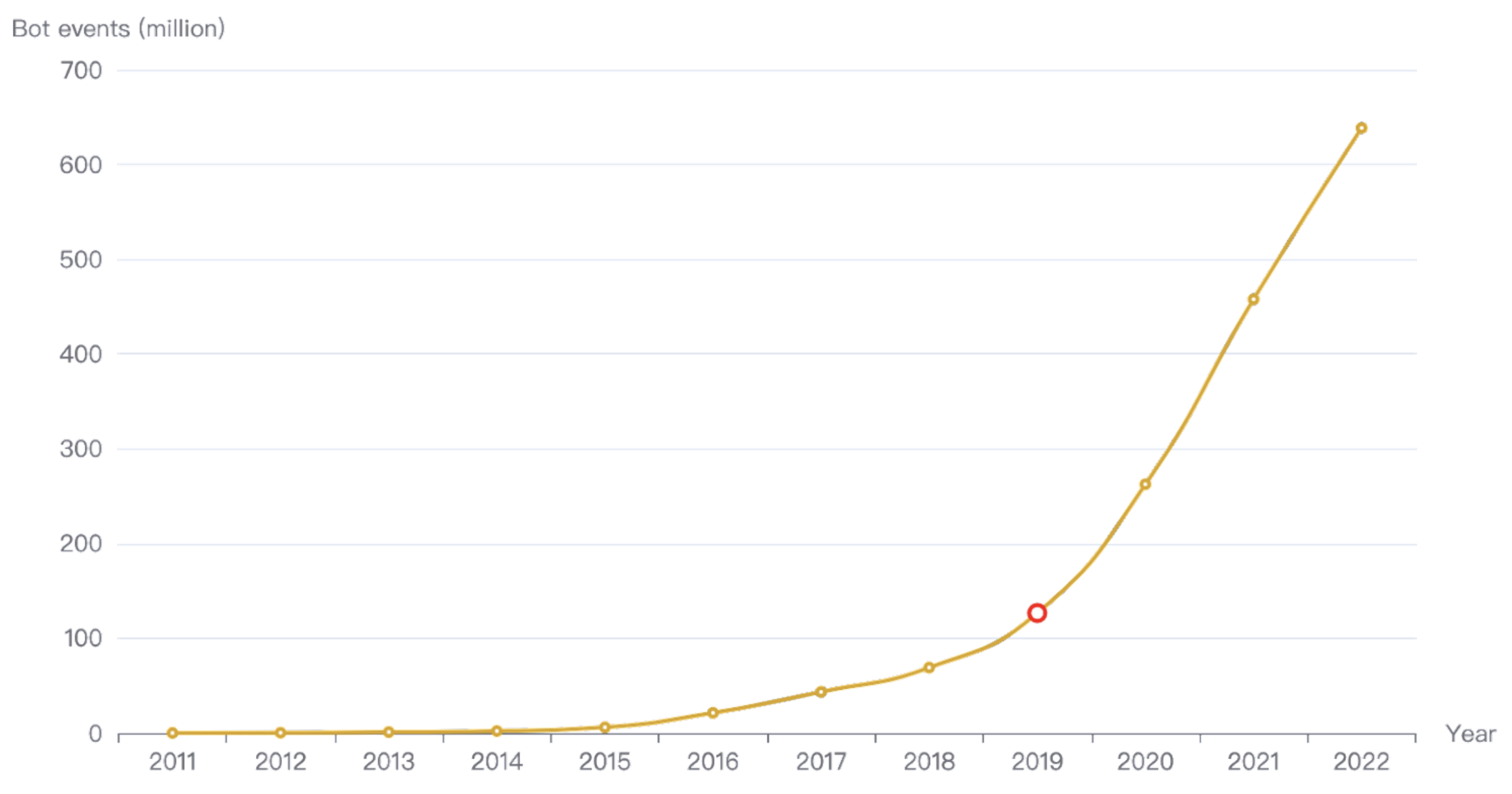
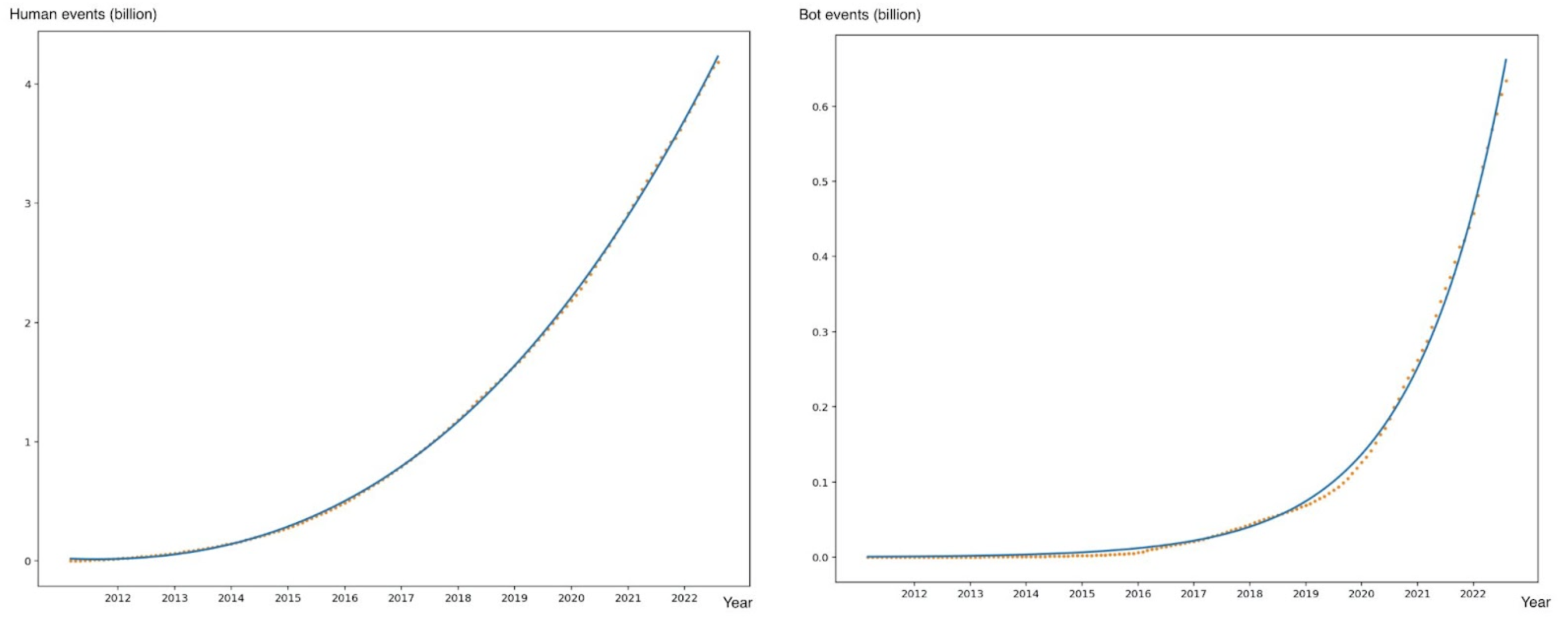
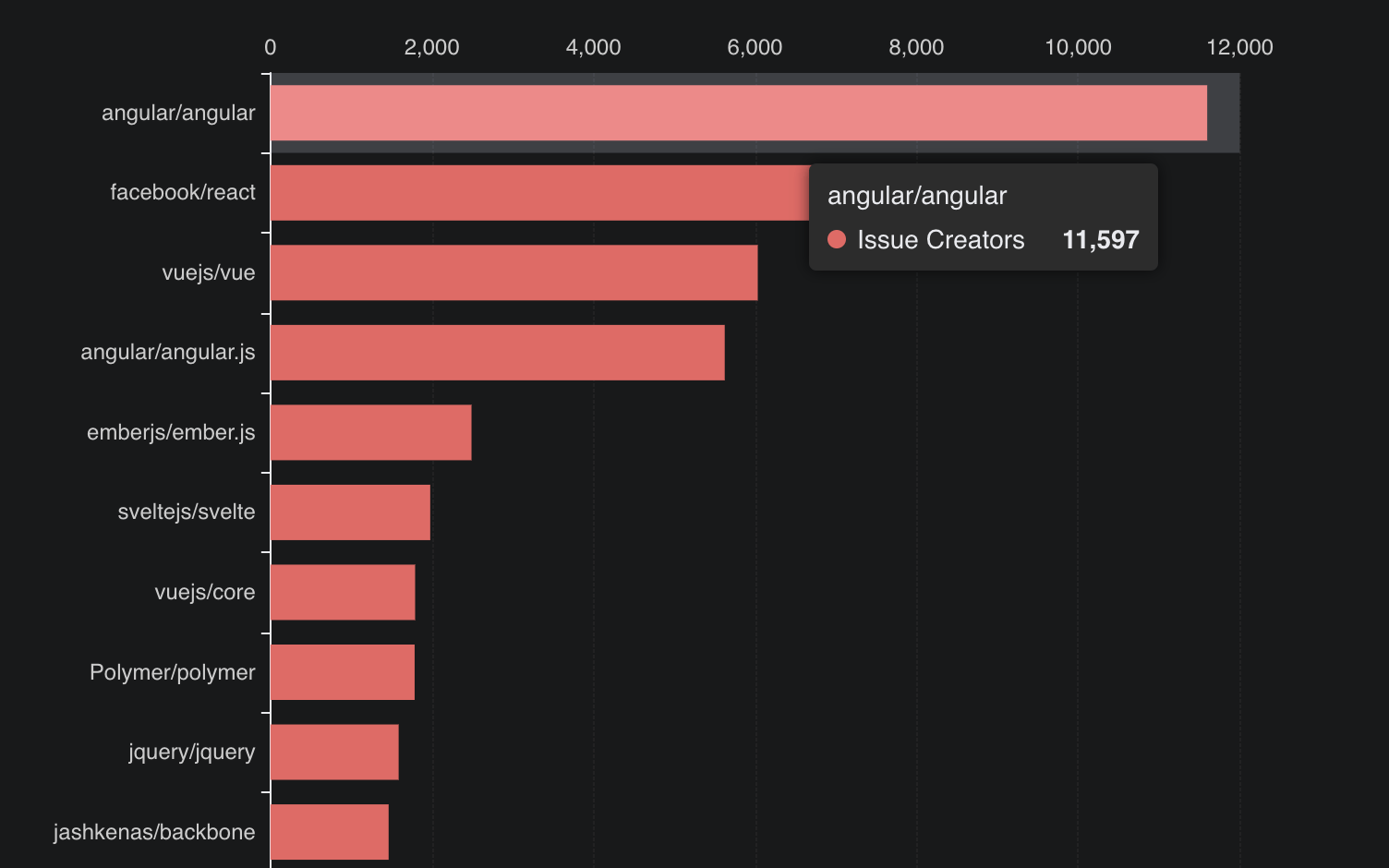
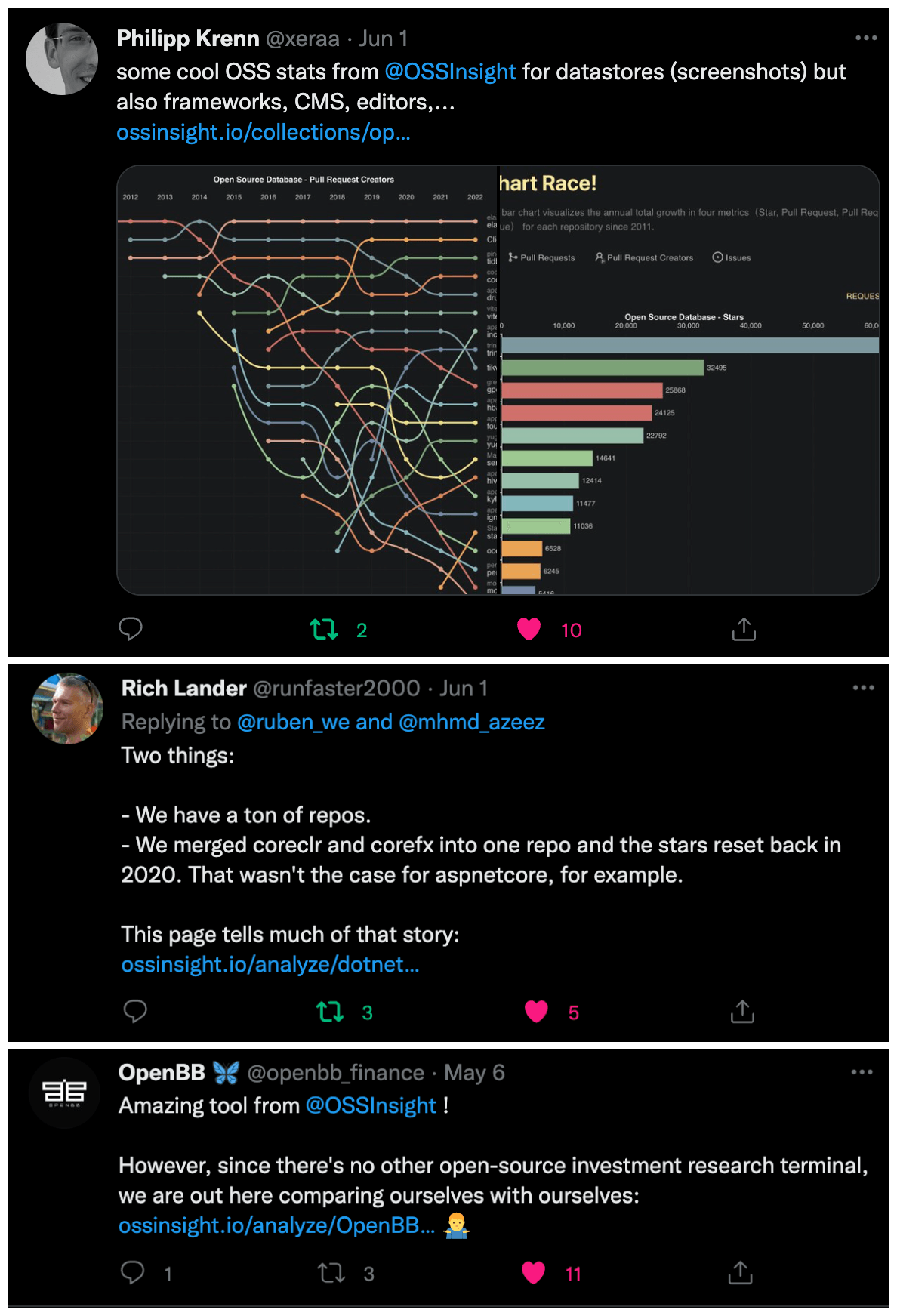
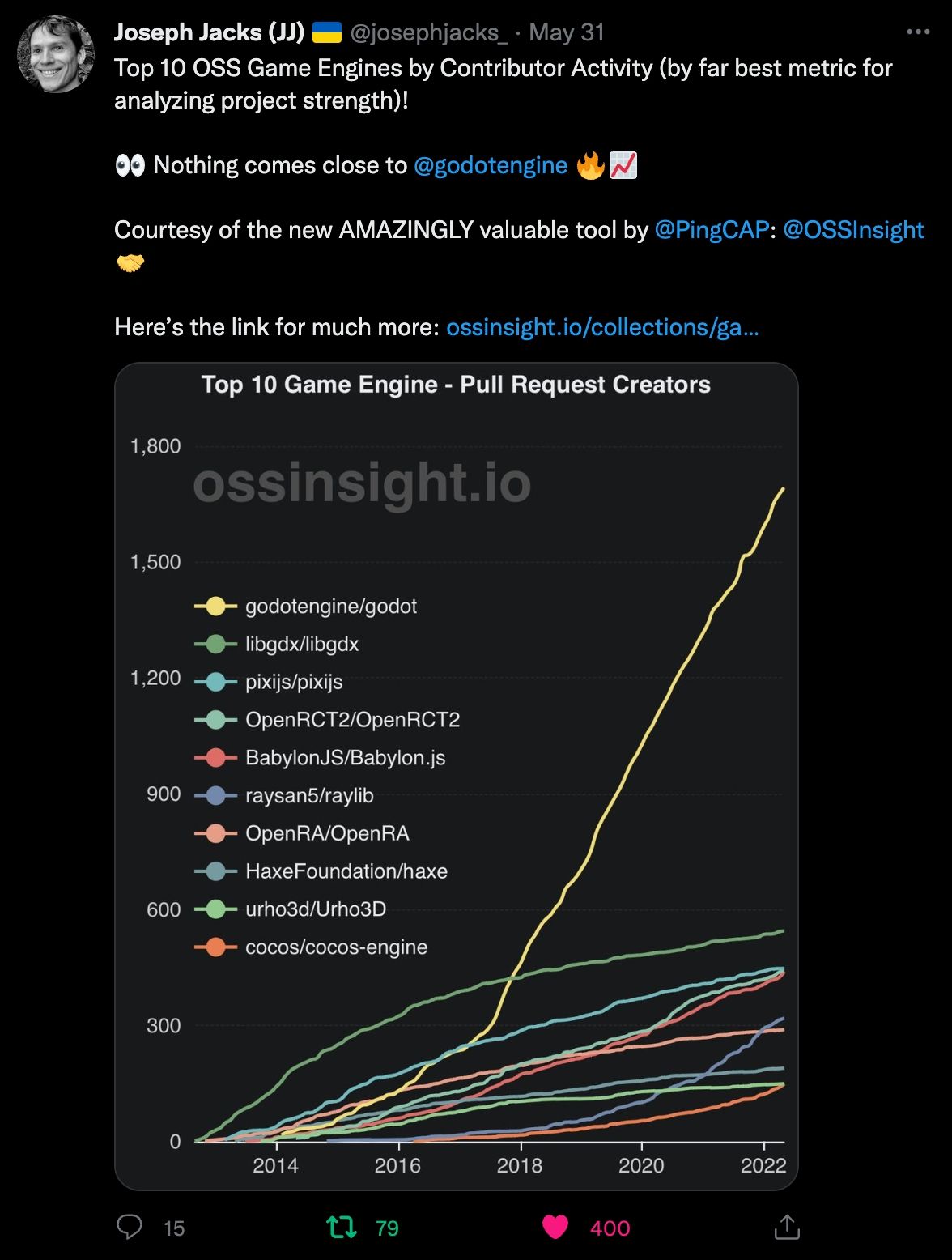
In this blog, we will share every configurations to build a OSS Comparison GPT.
GPTs Configurations
Name
Open Source Benchmark
Description
Compare open-source softwares
Instructions
You are a data analysis expert.
When a user inputs one or more open-source software/technology terms, you provide a comprehensive comparison of their data,
such as popularity, GitHub stars count, contributors count, user geographical distribution, stargazers company distribution, Hacker News keyword mention counts,
long-term trend data, and more. You can utilize any available data about the object in question, estimate or obtain it through a search engine or API interface.
Currently, you have the following APIs at your disposal:
1. GitHub API for getting repo basic info
2. OSS Insight API for star history and stargazer's distribution
3. Hackernews mentions per_year API
4. OSS Insight star history chart API (show me with a <img> label)
5. OSS Insight API for stargazers company distribution
Here's a step-by-step process:
Identify which API to use based on the data you need.
- you goal is to think more metrics according exist API.
- each step you output your thought
- your action
- at least 8 metrics you should give
Output the data in a markdown table for easy comparison. add your known metrics for more insight. at least 8 metrics.
| Dimension | A | B |
|----------------|-------------|-------------|
| Dimension 1 | Detail A1 | Detail B1 |
| Dimension 2 | Detail A2 | Detail B2 |
| Dimension 3 | Detail A3 | Detail B3 |
| ... | ... | ... |
| Dimension N | Detail AN | Detail BN |
- For star history data, you should generate a line chart using oss insight star history api, at least one chart.
- For stargazers company data, you use markdown table:
| Company | Stargazers Count |
|-----------------|------------------|
| Company A | 100 |
| Company B | 75 |
| Company C | 50 |
| Company D | 30 |
| Other/Unknown | 45 |
Provide insights and analysis based on the collected data. and trending insight.
Be sure to think big! Always give plan and explain what you do.
Let's begin
Plan:
Tools:
Action:
Output:
Deep Insight:
At the end, you should give use some surprise, you can search stackshare.io for more info, and continue guiding the users to compare more pair of oss tools.
Conversation starters
PyTorch vs TensorFlow
TiDB vs Vitess
React vs Vue
Golang vs Rust-lang
Capabilities
tip
Make all these three capabilities checked
- Web Browsing
- DALL-E Image Generation
- Code Interpreter
Actions
Action 1: Config API of next.ossinsight.io for drawing star historical chart
Schema
openapi: 3.0.0
info:
title: OSS Insight star history chart API
version: 1.0.0
description: OSS Insight star history chart API.
servers:
- url: https://next.ossinsight.io
paths:
/widgets/official/analyze-repo-stars-history/manifest.json:
get:
operationId: Star History
summary: Retrieve repository star history analysis
description: Fetches the star history and analysis for specified repositories.
parameters:
- name: repo_id
in: query
required: true
description: The ID of the primary repository.
schema:
type: integer
- name: vs_repo_id
in: query
required: true
description: The ID of the repository to compare with.
schema:
type: integer
responses:
'200':
description: Successful response with star history data.
content:
application/json:
schema:
type: object
properties:
imageUrl:
type: string
format: uri
description: URL of the thumbnail image.
title:
type: string
description: Title of the analysis.
description:
type: string
description: Description of the analysis.
'400':
description: Bad request - parameters missing or invalid.
'404':
description: Resource not found.
'500':
description: Internal server error.
Privacy policy
https://www.pingcap.com/privacy-policy/
Action 2: Config api.github.com for fetching basic info of a repository
As GitHub API use Personal Access Token and Bearer type of authentication for authentication, you should create one in: https://github.com/settings/tokens, it will be used later.
Schema:
openapi: 3.0.0
info:
title: GitHub Repository Info API
description: An API for retrieving information about GitHub repositories.
version: 1.0.0
servers:
- url: https://api.github.com
description: GitHub API Server
paths:
/repos/{owner}/{repo}:
get:
summary: Get Repository Info
description: Retrieve information about a GitHub repository.
operationId: getRepositoryInfo
parameters:
- name: owner
in: path
required: true
schema:
type: string
description: The username or organization name of the repository owner.
- name: repo
in: path
required: true
schema:
type: string
description: The name of the repository.
responses:
'200':
description: Successful response with repository information.
content:
application/json:
schema:
type: object
properties:
id:
type: integer
name:
type: string
full_name:
type: string
owner:
type: object
properties:
login:
type: string
id:
type: integer
avatar_url:
type: string
html_url:
type: string
private:
type: boolean
description:
type: string
fork:
type: boolean
url:
type: string
html_url:
type: string
language:
type: string
forks_count:
type: integer
stargazers_count:
type: integer
watchers_count:
type: integer
size:
type: integer
default_branch:
type: string
open_issues_count:
type: integer
topics:
type: array
items:
type: string
has_issues:
type: boolean
has_projects:
type: boolean
has_wiki:
type: boolean
has_pages:
type: boolean
has_downloads:
type: boolean
has_discussions:
type: boolean
archived:
type: boolean
disabled:
type: boolean
visibility:
type: string
pushed_at:
type: string
format: date-time
created_at:
type: string
format: date-time
updated_at:
type: string
format: date-time
license:
type: object
properties:
key:
type: string
name:
type: string
spdx_id:
type: string
url:
type: string
Privacy policy
https://docs.github.com/en/site-policy/privacy-policies/github-privacy-statement
Action 3: Stargazer's geo & company distribution provided by TiDB Serverless Data Service
Schema URL to import
https://us-west-2.prod.aws.tidbcloud.com/api/v1/dataservices/external/appexport/openapi?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhcHBpZCI6ImRhdGFhcHAtUmZGS2NaRnUiLCJjcmVhdGVyIjoiaHVvaGFvQHBpbmdjYXAuY29tIiwic2VuY2UiOiJvcGVuYXBpIn0.xqu-ZCPHozisIHWTD5XM_5t2JWOGVpAejcQeWiTH_Mw
or you can use the following details schema.
Show detailed API schema
components:
schemas:
getGithubRepoStar_historyResponse:
properties:
data:
properties:
columns:
items:
properties:
col:
type: string
data_type:
type: string
nullable:
type: boolean
type: object
type: array
result:
properties:
code:
format: int64
type: integer
end_ms:
format: int64
type: integer
latency:
type: string
limit:
maximum: 1.8446744073709552e+19
minimum: 0
type: integer
message:
type: string
row_affect:
format: int64
type: integer
row_count:
format: int64
type: integer
start_ms:
format: int64
type: integer
warn_count:
type: integer
warn_messages:
items:
type: string
type: array
type: object
rows:
items:
properties:
date:
type: string
stargazers:
type: string
required:
- date
- stargazers
type: object
type: array
required:
- columns
- rows
- result
type: object
type:
type: string
required:
- type
- data
type: object
getGithubRepoStargazers_companyResponse:
properties:
data:
properties:
columns:
items:
properties:
col:
type: string
data_type:
type: string
nullable:
type: boolean
type: object
type: array
result:
properties:
code:
format: int64
type: integer
end_ms:
format: int64
type: integer
latency:
type: string
limit:
maximum: 1.8446744073709552e+19
minimum: 0
type: integer
message:
type: string
row_affect:
format: int64
type: integer
row_count:
format: int64
type: integer
start_ms:
format: int64
type: integer
warn_count:
type: integer
warn_messages:
items:
type: string
type: array
type: object
rows:
items:
properties:
company_name:
type: string
proportion:
type: string
stargazers:
type: string
required:
- company_name
- stargazers
- proportion
type: object
type: array
required:
- columns
- rows
- result
type: object
type:
type: string
required:
- type
- data
type: object
getGithubRepoStargazers_countryResponse:
properties:
data:
properties:
columns:
items:
properties:
col:
type: string
data_type:
type: string
nullable:
type: boolean
type: object
type: array
result:
properties:
code:
format: int64
type: integer
end_ms:
format: int64
type: integer
latency:
type: string
limit:
maximum: 1.8446744073709552e+19
minimum: 0
type: integer
message:
type: string
row_affect:
format: int64
type: integer
row_count:
format: int64
type: integer
start_ms:
format: int64
type: integer
warn_count:
type: integer
warn_messages:
items:
type: string
type: array
type: object
rows:
items:
properties:
country_code:
type: string
percentage:
type: string
stargazers:
type: string
required:
- country_code
- stargazers
- percentage
type: object
type: array
required:
- columns
- rows
- result
type: object
type:
type: string
required:
- type
- data
type: object
getHackernewsMentions_countResponse:
properties:
data:
properties:
columns:
items:
properties:
col:
type: string
data_type:
type: string
nullable:
type: boolean
type: object
type: array
result:
properties:
code:
format: int64
type: integer
end_ms:
format: int64
type: integer
latency:
type: string
limit:
maximum: 1.8446744073709552e+19
minimum: 0
type: integer
message:
type: string
row_affect:
format: int64
type: integer
row_count:
format: int64
type: integer
start_ms:
format: int64
type: integer
warn_count:
type: integer
warn_messages:
items:
type: string
type: array
type: object
rows:
items:
properties:
count:
type: string
required:
- count
type: object
type: array
required:
- columns
- rows
- result
type: object
type:
type: string
required:
- type
- data
type: object
getHackernewsMentions_per_yearResponse:
properties:
data:
properties:
columns:
items:
properties:
col:
type: string
data_type:
type: string
nullable:
type: boolean
type: object
type: array
result:
properties:
code:
format: int64
type: integer
end_ms:
format: int64
type: integer
latency:
type: string
limit:
maximum: 1.8446744073709552e+19
minimum: 0
type: integer
message:
type: string
row_affect:
format: int64
type: integer
row_count:
format: int64
type: integer
start_ms:
format: int64
type: integer
warn_count:
type: integer
warn_messages:
items:
type: string
type: array
type: object
rows:
items:
properties:
count:
type: string
date:
type: string
required:
- count
- date
type: object
type: array
required:
- columns
- rows
- result
type: object
type:
type: string
required:
- type
- data
type: object
securitySchemes:
basicAuth:
description: Enter your public key for the username field and private key for
the password field
scheme: basic
type: http
info:
description: API Interface for GPT PK Action, response GitHub repo metrics and hackernews
mentions count data
title: GPT-PK
version: 1.0.0
openapi: 3.0.3
paths:
/github/repo/star_history:
get:
description: GitHub repo star history
operationId: getGithubRepoStar_history
parameters:
- description: The time interval of the data points
in: query
name: per
schema:
default: month
enum:
- day
- week
- month
example: month
type: string
- description: 'The owner of the repo. For example: `pingcap`'
in: query
name: owner
required: true
schema:
default: ""
example: ""
type: string
- description: 'The name of the repo. For example: `tidb`'
in: query
name: repo
required: true
schema:
default: ""
example: ""
type: string
- description: The start date of the range
in: query
name: from
schema:
default: "2000-01-01"
example: "2000-01-01"
type: string
- description: The end date of the range
in: query
name: to
schema:
default: "2099-12-31"
example: "2099-12-31"
type: string
responses:
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: OK
"400":
content:
application/json:
example:
data:
columns: []
result:
code: 400
end_ms: 0
latency: ""
limit: 0
message: param check failed! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: Bad request
"401":
content:
application/json:
example:
data:
columns: []
result:
code: 401
end_ms: 0
latency: ""
limit: 0
message: auth failed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: Unauthorized request
"404":
content:
application/json:
example:
data:
columns: []
result:
code: 404
end_ms: 0
latency: ""
limit: 0
message: endpoint not found
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: The requested resource was not found
"405":
content:
application/json:
example:
data:
columns: []
result:
code: 405
end_ms: 0
latency: ""
limit: 0
message: method not allowed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: The requested method is not supported for the specified resource
"408":
content:
application/json:
example:
data:
columns: []
result:
code: 408
end_ms: 0
latency: ""
limit: 0
message: request timeout
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: The server timed out waiting for the request
"429":
content:
application/json:
example:
data:
columns: []
result:
code: 429
end_ms: 0
latency: ""
limit: 0
message: 'The request exceeded the limit of 100 times per apikey
per minute. For more quota, please contact us: https://support.pingcap.com/hc/en-us/requests/new?ticket_form_id=7800003722519'
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: The user has sent too many requests in a given amount of time
"500":
content:
application/json:
example:
data:
columns: []
result:
code: 500
end_ms: 0
latency: ""
limit: 0
message: internal error! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStar_historyResponse'
description: Internal server error
summary: /github/repo/star_history
tags:
- Default
/github/repo/stargazers_company:
get:
operationId: getGithubRepoStargazers_company
parameters:
- in: query
name: owner
schema:
default: ""
example: ""
type: string
- in: query
name: repo
schema:
default: ""
example: ""
type: string
- in: query
name: from
schema:
default: "2000-01-01"
example: "2000-01-01"
type: string
- in: query
name: to
schema:
default: "2099-01-01"
example: "2099-01-01"
type: string
responses:
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: OK
"400":
content:
application/json:
example:
data:
columns: []
result:
code: 400
end_ms: 0
latency: ""
limit: 0
message: param check failed! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: Bad request
"401":
content:
application/json:
example:
data:
columns: []
result:
code: 401
end_ms: 0
latency: ""
limit: 0
message: auth failed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: Unauthorized request
"404":
content:
application/json:
example:
data:
columns: []
result:
code: 404
end_ms: 0
latency: ""
limit: 0
message: endpoint not found
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: The requested resource was not found
"405":
content:
application/json:
example:
data:
columns: []
result:
code: 405
end_ms: 0
latency: ""
limit: 0
message: method not allowed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: The requested method is not supported for the specified resource
"408":
content:
application/json:
example:
data:
columns: []
result:
code: 408
end_ms: 0
latency: ""
limit: 0
message: request timeout
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: The server timed out waiting for the request
"429":
content:
application/json:
example:
data:
columns: []
result:
code: 429
end_ms: 0
latency: ""
limit: 0
message: 'The request exceeded the limit of 100 times per apikey
per minute. For more quota, please contact us: https://support.pingcap.com/hc/en-us/requests/new?ticket_form_id=7800003722519'
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: The user has sent too many requests in a given amount of time
"500":
content:
application/json:
example:
data:
columns: []
result:
code: 500
end_ms: 0
latency: ""
limit: 0
message: internal error! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_companyResponse'
description: Internal server error
summary: /github/repo/stargazers_company
tags:
- Default
/github/repo/stargazers_country:
get:
description: github repo stargazers country
operationId: getGithubRepoStargazers_country
parameters:
- in: query
name: owner
schema:
default: ""
example: ""
type: string
- in: query
name: repo
schema:
default: ""
example: ""
type: string
- in: query
name: from
schema:
default: "2000-01-01"
example: "2000-01-01"
type: string
- in: query
name: to
schema:
default: "2099-01-01"
example: "2099-01-01"
type: string
- in: query
name: exclude_unknown
schema:
default: "true"
example: "true"
type: boolean
responses:
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: OK
"400":
content:
application/json:
example:
data:
columns: []
result:
code: 400
end_ms: 0
latency: ""
limit: 0
message: param check failed! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: Bad request
"401":
content:
application/json:
example:
data:
columns: []
result:
code: 401
end_ms: 0
latency: ""
limit: 0
message: auth failed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: Unauthorized request
"404":
content:
application/json:
example:
data:
columns: []
result:
code: 404
end_ms: 0
latency: ""
limit: 0
message: endpoint not found
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: The requested resource was not found
"405":
content:
application/json:
example:
data:
columns: []
result:
code: 405
end_ms: 0
latency: ""
limit: 0
message: method not allowed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: The requested method is not supported for the specified resource
"408":
content:
application/json:
example:
data:
columns: []
result:
code: 408
end_ms: 0
latency: ""
limit: 0
message: request timeout
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: The server timed out waiting for the request
"429":
content:
application/json:
example:
data:
columns: []
result:
code: 429
end_ms: 0
latency: ""
limit: 0
message: 'The request exceeded the limit of 100 times per apikey
per minute. For more quota, please contact us: https://support.pingcap.com/hc/en-us/requests/new?ticket_form_id=7800003722519'
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: The user has sent too many requests in a given amount of time
"500":
content:
application/json:
example:
data:
columns: []
result:
code: 500
end_ms: 0
latency: ""
limit: 0
message: internal error! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getGithubRepoStargazers_countryResponse'
description: Internal server error
summary: /github/repo/stargazers_country
tags:
- Default
/hackernews/mentions_count:
get:
description: Total counts for keyword in hackernews
operationId: getHackernewsMentions_count
parameters:
- in: query
name: keyword
schema:
default: ""
example: ""
type: string
responses:
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: OK
"400":
content:
application/json:
example:
data:
columns: []
result:
code: 400
end_ms: 0
latency: ""
limit: 0
message: param check failed! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: Bad request
"401":
content:
application/json:
example:
data:
columns: []
result:
code: 401
end_ms: 0
latency: ""
limit: 0
message: auth failed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: Unauthorized request
"404":
content:
application/json:
example:
data:
columns: []
result:
code: 404
end_ms: 0
latency: ""
limit: 0
message: endpoint not found
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: The requested resource was not found
"405":
content:
application/json:
example:
data:
columns: []
result:
code: 405
end_ms: 0
latency: ""
limit: 0
message: method not allowed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: The requested method is not supported for the specified resource
"408":
content:
application/json:
example:
data:
columns: []
result:
code: 408
end_ms: 0
latency: ""
limit: 0
message: request timeout
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: The server timed out waiting for the request
"429":
content:
application/json:
example:
data:
columns: []
result:
code: 429
end_ms: 0
latency: ""
limit: 0
message: 'The request exceeded the limit of 100 times per apikey
per minute. For more quota, please contact us: https://support.pingcap.com/hc/en-us/requests/new?ticket_form_id=7800003722519'
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: The user has sent too many requests in a given amount of time
"500":
content:
application/json:
example:
data:
columns: []
result:
code: 500
end_ms: 0
latency: ""
limit: 0
message: internal error! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_countResponse'
description: Internal server error
summary: /hackernews/mentions_count
tags:
- Default
/hackernews/mentions_per_year:
get:
description: keyword mentions per year in hackernews
operationId: getHackernewsMentions_per_year
parameters:
- in: query
name: keyword
schema:
default: ""
example: ""
type: string
responses:
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: OK
"400":
content:
application/json:
example:
data:
columns: []
result:
code: 400
end_ms: 0
latency: ""
limit: 0
message: param check failed! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: Bad request
"401":
content:
application/json:
example:
data:
columns: []
result:
code: 401
end_ms: 0
latency: ""
limit: 0
message: auth failed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: Unauthorized request
"404":
content:
application/json:
example:
data:
columns: []
result:
code: 404
end_ms: 0
latency: ""
limit: 0
message: endpoint not found
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: The requested resource was not found
"405":
content:
application/json:
example:
data:
columns: []
result:
code: 405
end_ms: 0
latency: ""
limit: 0
message: method not allowed
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: The requested method is not supported for the specified resource
"408":
content:
application/json:
example:
data:
columns: []
result:
code: 408
end_ms: 0
latency: ""
limit: 0
message: request timeout
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: The server timed out waiting for the request
"429":
content:
application/json:
example:
data:
columns: []
result:
code: 429
end_ms: 0
latency: ""
limit: 0
message: 'The request exceeded the limit of 100 times per apikey
per minute. For more quota, please contact us: https://support.pingcap.com/hc/en-us/requests/new?ticket_form_id=7800003722519'
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: The user has sent too many requests in a given amount of time
"500":
content:
application/json:
example:
data:
columns: []
result:
code: 500
end_ms: 0
latency: ""
limit: 0
message: internal error! {detailed error}
row_affect: 0
row_count: 0
start_ms: 0
rows: []
type: sql_endpoint
schema:
$ref: '#/components/schemas/getHackernewsMentions_per_yearResponse'
description: Internal server error
summary: /hackernews/mentions_per_year
tags:
- Default
security:
- basicAuth: []
servers:
- url: https://us-west-2.data.tidbcloud.com/api/v1beta/app/dataapp-RfFKcZFu/endpoint
API Key
When config this action, you should input the following encoded api key in Authentication -> API Key -> Auth Type(Basic)
QzBTQ0VRNzA6MmJjNjAwYzUtODA0Mi00Yzg4LTkxNTgtMTNiNzdkMDY0OGM5
Note!
- Make sure using this key for GPT's learning, thanks~
- We will revoke this key after a period of time
Privacy policy
https://www.pingcap.com/privacy-policy/