From Runtimes to Recipes: Why Skill Repositories Are Outgrowing Agent Frameworks
In early 2026, skill-pack repositories on GitHub are attracting stars 1.5× faster than agent runtimes in the same launch window. We analyzed 8 fast-growing repositories to understand why the value layer is moving from execution engines to distribution and workflows.

In early 2026, a subtle inversion is happening in the AI agent ecosystem:
the repositories shipping skills, workflows, and setup conventions are now growing faster than the repositories shipping agent runtimes.
We analyzed 8 fast-growing repositories created in Jan-Feb 2026, split into two groups:
- Skill Layer (distribution/workflow packs):
- Runtime Layer (execution engines/frameworks):
Core finding: the Skill Layer group is averaging 731 stars/day, while Runtime Layer averages 474 stars/day - a 1.54× speed advantage in the same time window.
Snapshot Table (Verified via GitHub API)
| Repository | Category | Stars | Forks | Contributors | Open Issues | Created | Stars/Day | Fork Ratio | Issue Ratio |
|---|---|---|---|---|---|---|---|---|---|
| affaan-m/everything-claude-code | Skill Layer | 120,120 | 15,586 | 137 | 103 | 2026-01-18 | 1,646.8 | 0.130 | 0.001 |
| VoltAgent/awesome-openclaw-skills | Skill Layer | 43,218 | 4,117 | 76 | 14 | 2026-01-25 | 664.9 | 0.095 | 0.000 |
| sickn33/antigravity-awesome-skills | Skill Layer | 28,955 | 4,838 | 153 | 2 | 2026-01-14 | 378.0 | 0.167 | 0.000 |
| kepano/obsidian-skills | Skill Layer | 18,432 | 1,086 | 11 | 21 | 2026-01-02 | 207.0 | 0.059 | 0.001 |
| HKUDS/nanobot | Runtime Layer | 37,130 | 6,390 | 203 | 895 | 2026-02-01 | 638.4 | 0.172 | 0.024 |
| sipeed/picoclaw | Runtime Layer | 26,801 | 3,748 | 194 | 318 | 2026-02-04 | 490.8 | 0.140 | 0.012 |
| qwibitai/nanoclaw | Runtime Layer | 26,007 | 9,779 | 63 | 573 | 2026-01-31 | 440.8 | 0.376 | 0.022 |
| vercel-labs/agent-browser | Runtime Layer | 25,812 | 1,564 | 96 | 336 | 2026-01-11 | 326.7 | 0.061 | 0.013 |
Data snapshot time: 2026-03-31 UTC. Stars/day = current stars / days since repo creation. Contributors counted from paginated GitHub contributors API (anon=1).
Chart 1 - Star Velocity Is Moving Up the Stack
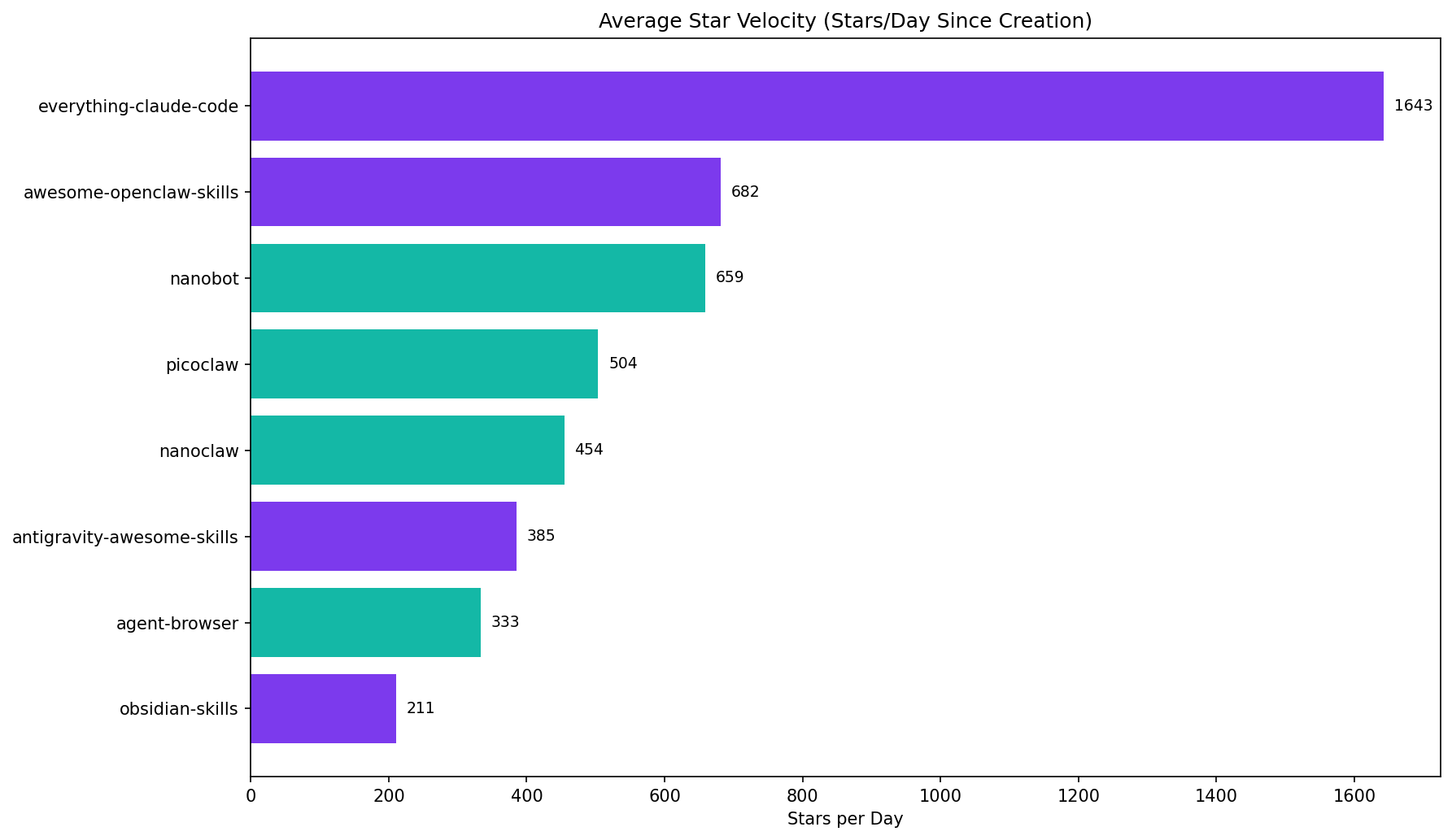
The top repo is a skill-pack distribution project, not a runtime engine:
- everything-claude-code: 1,647 stars/day
- best runtime in this cohort (nanobot): 638 stars/day
That is not a small gap; it is a product-layer shift.
Chart 2 - Issue Pressure: 35× Difference
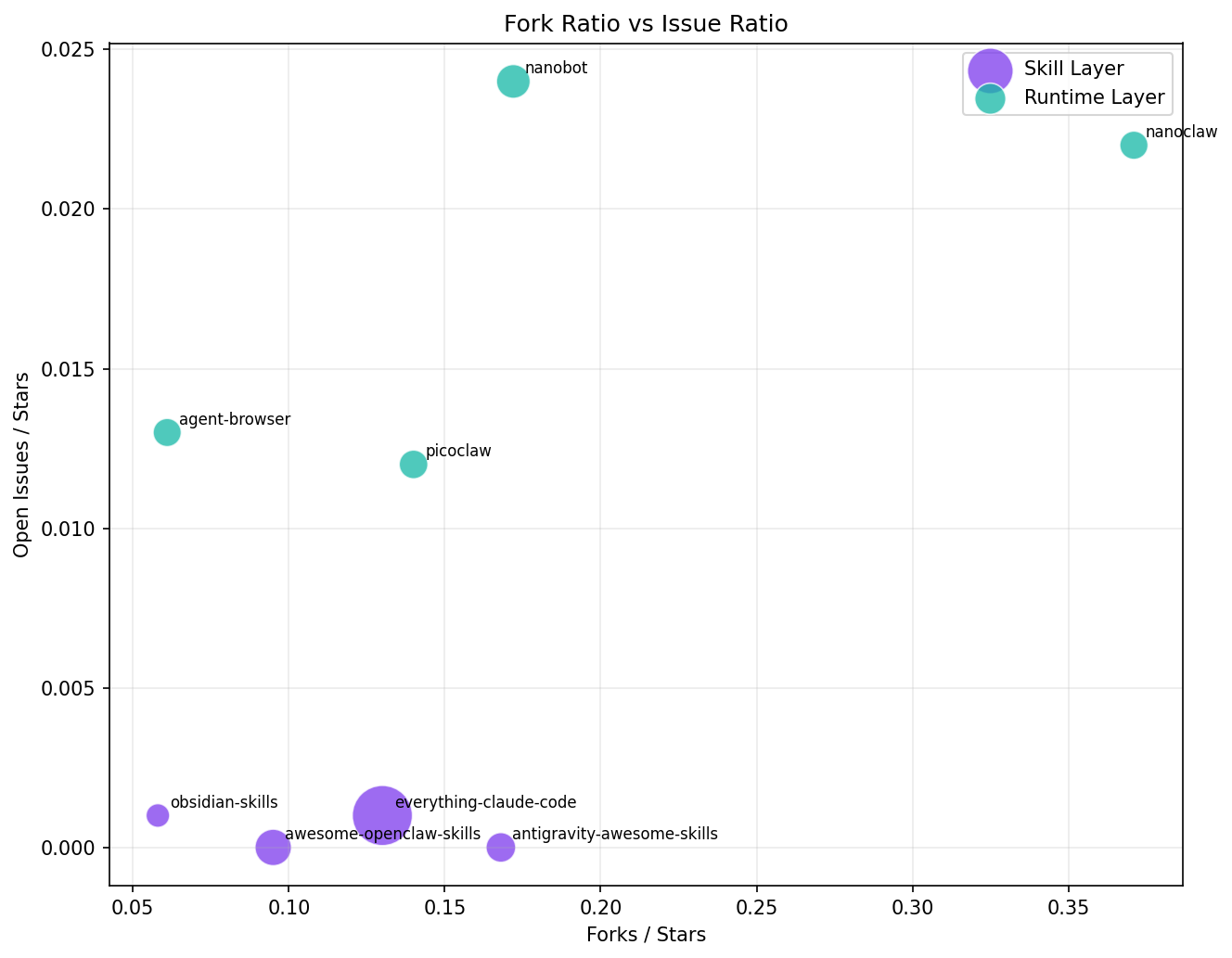
Average issue ratio:
- Skill Layer: 0.0005
- Runtime Layer: 0.0178
Runtime repos carry roughly 35× higher issue pressure.
This matters because stars are easy to acquire, but issue queues are where maintenance cost lives. Skill repositories are behaving more like distribution/media products; runtime repositories are behaving like infrastructure products.
Chart 3 - Contributor Economics
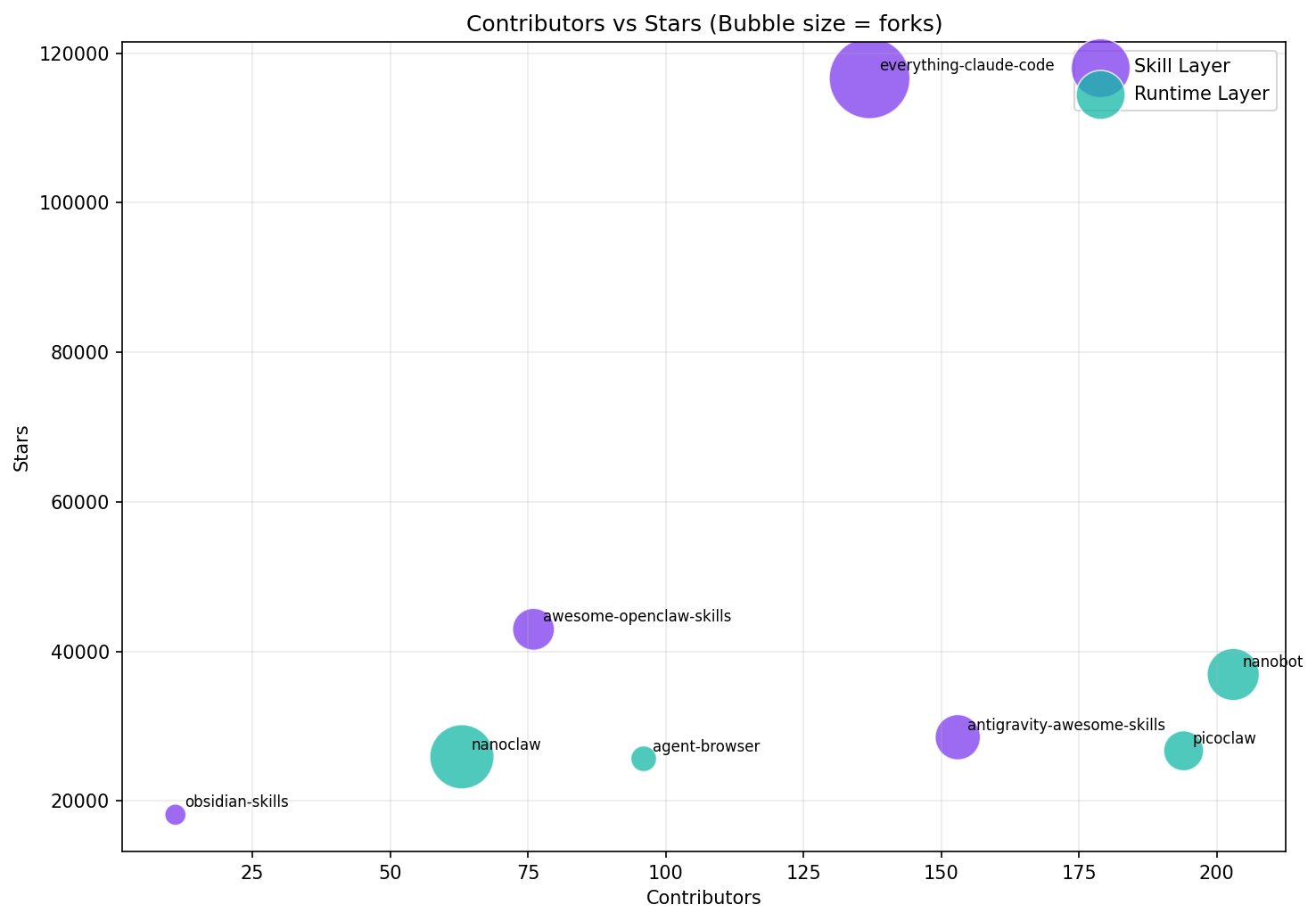
Median stars per contributor:
- Skill Layer: 708.4
- Runtime Layer: 224.5
Skill repositories are extracting significantly more star attention per maintainer.
What the Code Says (Not Just README Narratives)
To understand why this pattern exists, we looked at source-level implementation details from one skill-layer project and one runtime-layer project.
1) Skill Layer is becoming an installer + policy system
In affaan-m/everything-claude-code, the architecture is not a monolithic runtime. It is a distribution control plane:
.mcp.jsonwires multiple MCP servers (github,context7,memory,playwright,sequential-thinking) throughnpxor remote endpoints.install.shbootstraps dependencies and delegates toscripts/install-apply.js.docs/SKILL-PLACEMENT-POLICY.mdexplicitly separates curated vs learned/imported/evolved skills, with provenance requirements and "not shipped" boundaries.
That is effectively a package/distribution strategy for agent capabilities, not just a prompt collection.
2) Runtime Layer is optimizing execution core complexity
In HKUDS/nanobot, the codebase includes an explicit core-line accounting script (core_agent_lines.sh) that computes line counts while excluding channels/providers/skills.
The script's central message is architectural prioritization: keep the execution brain small and auditable, and treat integrations as peripheral modules.
This is a fundamentally different optimization target from skill-layer repos. Runtime projects optimize correctness, performance, and stability under execution load. Skill-layer projects optimize adoption, transferability, and composition speed.
Caveats: What This Data Doesn't Prove
Before naming the pattern, three limitations deserve honest treatment.
Sample size is small. Four vs. four is a directional signal, not statistical proof. We chose these eight because they are the fastest-growing repos in each category from the same launch window, but a different selection could yield a different ratio. Take the 1.5× multiplier as an observation, not a law.
Awesome-lists have a structural star advantage. Repositories like everything-claude-code and awesome-openclaw-skills are curated collections — they're low-friction to star (you get value by bookmarking), while runtime repos demand installation, debugging, and commitment before a star feels earned. Some of the velocity gap is explained by this engagement asymmetry, not just a "value layer shift." The fork ratio data partially controls for this: antigravity-awesome-skills at 16.7% fork ratio and everything-claude-code at 13.0% show that people are also cloning and modifying, not just bookmarking. But the confound is real.
The "Skill Layer" category mixes apples and oranges. obsidian-skills ships actual executable skill files; awesome-openclaw-skills is closer to a directory. Grouping them under one label stretches the definition. We kept both because the growth pattern holds across the group, but readers should note the heterogeneity.
With those caveats registered:
The Pattern: "Distribution Layer Inversion"
We can name the pattern like this:
Distribution Layer Inversion = in early category formation, growth moves from execution engines to packaged workflows once runtime capability becomes "good enough."
Boundary conditions (where this pattern should hold):
- Multiple compatible runtimes already exist.
- Users face workflow/setup friction more than core model/runtime limitations.
- Repo value can be copied/applied immediately without deep architectural decisions.
When these three are true, stars flow to repositories that reduce "time-to-first-useful-result," not necessarily to those that improve engine internals.
So What?
If you are building in this space:
- Runtime maintainers should expect heavier support burden and slower star velocity relative to distribution projects.
- Skill/distribution maintainers have a growth tailwind, but must invest in provenance, safety, and version compatibility across runtimes.
- Investors and ecosystem analysts should stop using stars alone and track at least three ratios together: stars/day, issue ratio, and stars-per-contributor.
Because in 2026, the winning layer is increasingly not "who executes tokens fastest," but "who packages usable intelligence fastest."
Methodology note: All quantitative metrics in this article were collected from public GitHub REST API endpoints on 2026-03-31 UTC (/repos/{owner}/{repo}, /contributors paginated). OSSInsight links are provided for each repository for independent exploration.