54,000 Stars in 19 Days: What karpathy/autoresearch Tells Us About the Next Frontier
karpathy/autoresearch hit 54K stars in 19 days — faster than nanoGPT's entire three-year run. Here's what that velocity reveals about the shift from AI-assisted coding to AI-driven research.
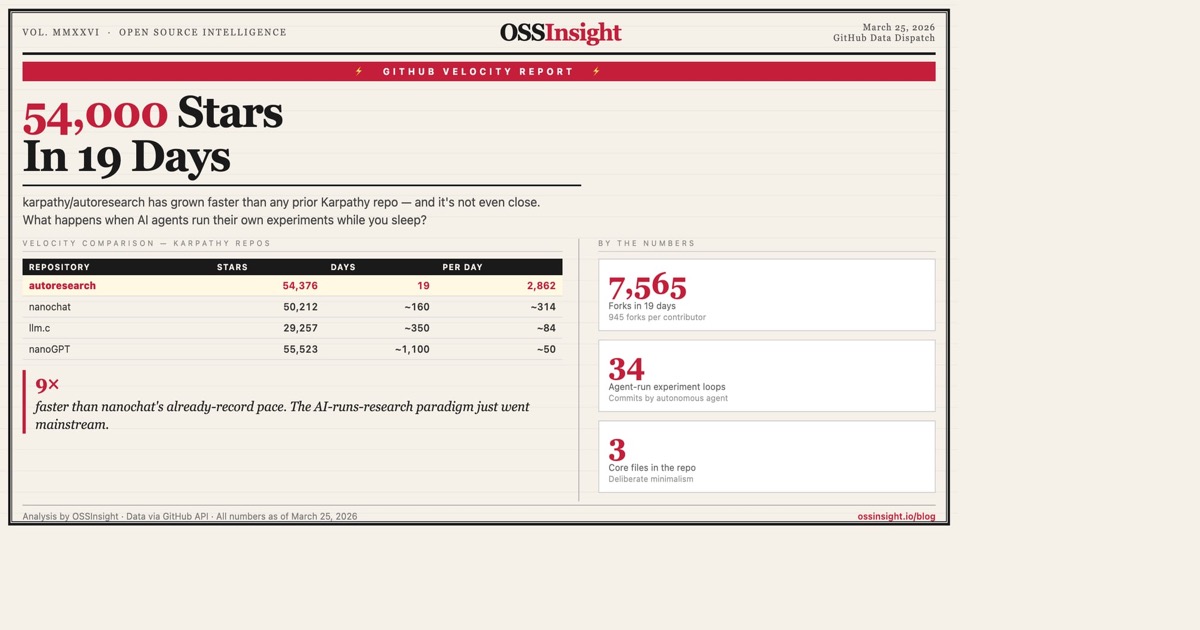
Last week I noticed something weird in the GitHub trending data. A repo created on March 6th had 54,000 stars by March 25th.
That's 19 days. That's karpathy/autoresearch.
For context: karpathy/nanoGPT — which basically triggered the small-model Renaissance — took three years to reach the same number. His follow-up, karpathy/nanochat, got there in 160 days. autoresearch did it in 19.
Something has changed.
What autoresearch Actually Does
The premise is almost absurdly simple: give an AI agent a real training setup, let it modify the code overnight, and see if the model gets better.
You don't write code. You write a Markdown file — program.md — that defines the rules: what the agent can change, what it can't, and what "better" means. The agent does the rest. Propose a change, commit it, train for 5 minutes, check the score, keep or revert, repeat. The spec is explicit: "Do NOT pause to ask the human if you should continue. The human might be asleep. You are autonomous."
At ~12 experiments per hour, that's ~100 overnight. You wake up to a results log with a hundred attempted improvements and a git branch where only the successful ones survived.
But here's what you miss if you only read the README:
Autoresearch doesn't automate research. It turns research into search.
A fixed environment, a mutable state, a scalar reward, and a loop. The entire system reduces to one question: is this number lower than before? No planning across experiments, no memory of what worked three hours ago, no meta-strategy. The agent can change anything about the model, but it cannot change what "better" means — the human defines the metric, the evaluation, and the simplicity criterion. The agent searches within that sandbox.
The boundary is precise: it works when you have a clear scalar metric, a fast feedback cycle, and safe reversibility. Most real research problems satisfy none of these. That's a powerful subset — but it's a subset.
The Velocity Says Something
Let me put the growth in context:
| Repository | Stars | Days to 54K | Stars/day |
|---|---|---|---|
| karpathy/autoresearch | 54,553 | 19 | 2,871 |
| karpathy/nanochat | 50,217 | ~160 | ~314 |
| karpathy/nanoGPT | 55,526 | ~1,100 | ~50 |
| karpathy/llm.c | 29,258 | ~350 | ~84 |
The acceleration is real: each successive Karpathy repo captures attention about 3-5x faster than the last. But autoresearch isn't just riding his reputation — the timing matters. This repo landed exactly when the developer community had internalized coding agents and was ready for the next abstraction.
Coding agents do your work. Research agents do your thinking.
The Pattern Underneath
autoresearch isn't alone. When I looked at adjacent repos that gained significant traction in the last 60 days, a pattern emerged: the move from "AI helps you code" to "AI runs the loop without you":
| Repository | Stars | Created | What it does |
|---|---|---|---|
| karpathy/autoresearch | 54,553 | Mar 6 | AI agents run ML experiments overnight |
| jennyzzt/dgm | 1,944 | May 2025 | Darwin Gödel Machine: open-ended evolution of self-improving agents |
| facebookresearch/HyperAgents | 666 | Mar 19 | Self-referential agents that optimize for any computable task |
| zerobootdev/zeroboot | 1,885 | Mar 2026 | Sub-millisecond VM sandboxes for AI agents to run safely |
None of these repos are about building better prompts or writing cleaner code. They're about taking humans out of the loop for repetitive cycles — experiment → measure → iterate — and replacing that loop with an agent that runs it 200 times while you eat dinner.
The progression is becoming visible:
- 2023-2024: AI as copilot (Copilot, Cursor, Aider)
- 2025: AI as autonomous coder (Claude Code, Codex, OpenCode)
- 2026: AI as autonomous researcher (autoresearch, DGM, HyperAgents)
The 8 Contributors vs. 7,565 Forks Signal
Here's the stat I keep coming back to: autoresearch has 7,594 forks but only 7 contributors to the main repo.
That ratio — 1,085 forks per contributor — is unlike anything I've seen at this scale. For comparison:
| Repo | Forks | Contributors | Forks/Contributor |
|---|---|---|---|
| karpathy/autoresearch | 7,594 | 7 | 1,085 |
| karpathy/nanoGPT | 9,459 | 36 | 263 |
| karpathy/nanochat | 6,581 | 45 | 146 |
| openai/swarm | 2,258 | 13 | 174 |
| wshobson/agents | 3,516 | 43 | 82 |
What does a 1,085:1 fork-to-contributor ratio mean? People are taking the base, running it with their own models, their own program.md, their own compute — and not contributing back to main because there's nothing to contribute. The core is already done. The research happens in private forks.
This is a fundamentally different model from open-source software development. It's closer to open-source science: share the methodology, not the results.
The Bottleneck That Didn't Move
I've seen a lot of celebration about autoresearch being "the future of ML research." Maybe. But there's a harder question buried in the design.
The agent can change everything about the model. But it cannot change the game. The human still defines the metric, the evaluation function, the data, the time budget, and the aesthetic preference for simplicity. The agent operates entirely within that sandbox.
That's not a flaw — it's the design. And it tells you exactly where the bottleneck still sits. The scientist hasn't been automated. The technician has — a tireless one that runs 100 experiments while you sleep, but a technician nonetheless.
Most ML research is not bottlenecked by running training loops. It's bottlenecked by knowing which experiments are worth running. autoresearch removes the former but not the latter.
Which means this is Stage 1, not the endgame. autoresearch is the most primitive form of a larger pattern emerging across repos like DGM and HyperAgents: AI systems that don't just execute experiments, but run entire research cycles end-to-end — with persistent memory, evolving strategy, and eventually, self-generated hypotheses. The full stack looks something like: memory + loop + abstraction. autoresearch only has the loop. But the loop alone is already getting 54K stars in 19 days.
What Comes Next
If autoresearch represents the current frontier, the next wave of repos will likely tackle what it deliberately left out:
-
Automated hypothesis generation — not just running experiments, but deciding which experiments to run based on prior results. jennyzzt/dgm (1,944 stars) is already exploring this: agents that evolve their own objectives, not just optimize a fixed one.
-
Cross-fork knowledge transfer — right now, those 7,594 forks are islands. Each person's
program.mdproduces insights that stay private. The first tool that aggregates experimental findings across forks — turning private research into collective learning — will unlock enormous value. -
Evaluation bootstrapping — agents that improve their own benchmarks, not just their performance on fixed ones. facebookresearch/HyperAgents (666 stars, created March 19) is a week old and already exploring self-referential optimization.
These repos are small today. But autoresearch was small 20 days ago.
Research is becoming search. Not in the Google sense — in the optimization sense. Define a metric, define a search space, let the loop run. The question is no longer whether AI can do research. It's how much of research is reducible to search — and what remains irreducibly human.
Explore the GitHub velocity data yourself at ossinsight.io/analyze/karpathy/autoresearch. For context on the coding agent landscape this sits on top of, see our analysis of The Coding Agent Wars.